networkx - community detection - label propagation(semi-sync)
3-line summary
- async label propagation은 매우 오래 걸리고, sync 방법은, bipartite network에서 발산하는 경우가 있어서, Community Detection via Semi-Synchronous Label Propagation Algorithms에서 semi-sync를 제시함.
- 더 빠르고, 다른 지표들도 딱히 달라지지 않음. node coloroing을 사용해서, node를 구분하고 구분한 그룹별로 기존의 async label propagation을 적용
- 또한, 이웃의 최빈 label들이 2개 이상일 때 원래는 ‘random.choice’를 사용했지만, 여기서는 가장 큰 값의 label을 정하는 것이 차이.
semi-sync Label Propagation
- Label propagation은 “클래스가 식별되지 않은(unlabeled) 데이터 포인트에 클래스를 지정해주는 semi-supervised ML 알고리즘”을 말합니다. 특히, 아주 적은 수의 data들(혹은 Node)들만이 label을 가지고 있다고 한다면, 이 알고리즘을 통해, class를 증폭시켜줄 수 있죠. 아래 그림을 통해 보면 더 명확할 수 있는데, “내 커뮤니티는 내 이웃이 가장 많이 속한 커뮤니티와 같다”는 개념으로, 커뮤니티를 찾아나가는 방식이라고 보시면 됩니다.
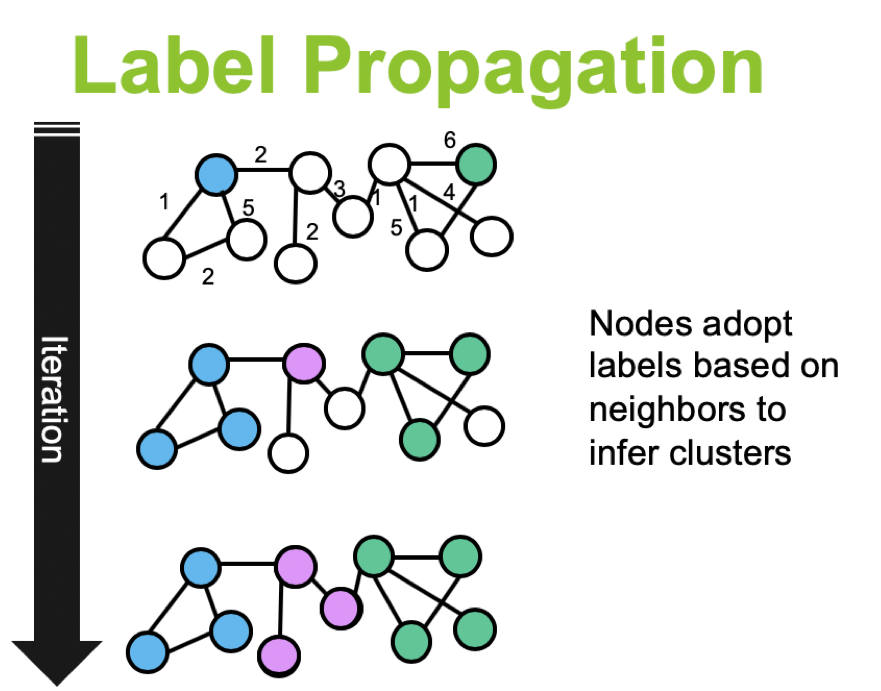
- 그 외로도, Community Detection via Semi-Synchronous Label Propagation Algorithms에서는 “반동기적인 방식으로, 속도뿐만 아니라, 안정성도 찾았다”라고 주장합니다.
- 기존의 방식인 async의 경우 모든 노드를 일일이 건드려야 하므로 느리고,
- 이전의 node label을 참고하는 sync 방식의 경우는 bipartite network에서 발산하는 경우가 있었죠.
- 따라서, 새로 제시되는 semi-sync 에서는 다른 접근 법으로 빠르고, 발산하지 않는 값을 찾았다고 합니다. 그리고, 그 방식의 키는 ‘node coloring’을 통해, 서로 인접하지 않은 노드들 그룹별로 따로 처리해주는 것이죠.
Algorithm
1) Node coloring: coloring을 통해서 color가 다른 node 그룹을 뽑는다. 2) Async label propagation: 그리고 이 그룹별로 기존의 label propagation을 동일하게 진행함. 다만, 기존의 방식에서는 최빈도가 같은 여러 라벨이 동시에 존재할 때, random.choice를 수행했으나, 여기서는 label이 가장 높은 놈을 선택한다는 것만 차이가 있음. 3) Termination: 모든 노드가 업데이트될 필요가 없을 때, 종료.
- 간단합니다. coloring을 통해 나누고 그룹별로 처리하는 것과, 여러 최빈라벨이 있을 때, 선택하는 방식만 다른 것이죠.
Implement semi-sync LPA by myself.
- 따라서, graph
G로부터, semi-sync label propagation을 사용하는 방법을 다음과 같이 구현하였습니다. - networkx - label_propagation_communities를 참고하였습니다만, 이상하게 제 속도가 더 빠르네요 흠.
import networkx as nx
import time
import collections
import numpy as np
import functools
def custom_sync_LPA(G):
"""
1) coloring을 통해서 color가 다른 node 그룹을 뽑는다.
2) 서로 다른 color를 가진 그룹별로 각각, node label을 업데이트한다. 업데이트 방식은 동일
- 다만, 최빈도가 같은 여러 라벨이 존재할 때, label 값이 가잔 높은 놈을 선택한다는 것에만 차이가 있음.
3) 더이상 노드가 업데이트될 필요가 없을때(즉, 업데이트해도 같은 값일 때), termination.
"""
def _color_nodes_dict(G):
# greedy_color를 사용하여 node를 색칠하고,
# dict(color: [node, node])를 리턴함.
node_color_dict = nx.greedy_color(G, strategy='largest_first')
color_nodes_dict = {}
for node, color in node_color_dict.items():
if color in color_nodes_dict:
color_nodes_dict[color].append(node)
else:
color_nodes_dict[color] = [node]
return color_nodes_dict
def _most_frequent_labels(node, G, node_labels):
# `node`의 neighbor 중에서 가장 빈도가 높은 label을 선택하여 리턴.
# 1개 이상일 경우 random.choose.
node_nbrs = G[node]
if len(node_nbrs)==0:# nbr이 없으므로 원래 label을 그대로 리턴함.
return {node_labels[node]}
else:
nbr_labels = [node_labels[v] for v in node_nbrs]
nbr_label_counter = dict(collections.Counter(nbr_labels))
max_label_freq = max(nbr_label_counter.values())
best_labels = {
node_label
for node_label, label_freq in nbr_label_counter.items()
if label_freq == max_label_freq
}
return best_labels
def _update_node_label(node, G, node_labels):
# `node`의 label을 update
# asyncronous LPA 에서는 이 값을 random하게 골랐다면,
# 여기서는, 가장 큰 값을 선택함.
best_labels = _most_frequent_labels(node, G, node_labels)
if len(best_labels)==1:
node_labels[node] = best_labels.pop()
else:
if node_labels[node] not in best_labels:
node_labels[node] = max(best_labels)
def _check_termination_condition(node_labels, G):
# 모든 노드가 현재 node label이 nbr을 참고하여 업데이트될 새로운 node와 같아야. 알고리즘을 종료
for node, existing_node_label in node_labels.items():
if len(G[node]) > 0:
if existing_node_label not in _most_frequent_labels(node, G, node_labels):
# 현재 nodel label과 nbr에 기반한 node label이 다르므로, termination 할 수 없음.
return False
return True
"""
return all(
node_labels[node] in _most_frequent_labels(node, G, node_labels)
for node in G if len(G[node]) > 0)
"""
## Function definition Done.
################################################
# 1) coloring을 통해서 서로 인접하지 않은 node 집합들을 뽑고,
color_nodes_dict = _color_nodes_dict(G)
# 2) 각 node의 label을 unique하게 initialize하고.
node_labels = {n:i for i, n in enumerate(G)}
# 3) 모든 노드가 현재 node label과 이웃들에게 가장 많이 나타나는 label이 같을 경우 termination
while _check_termination_condition(node_labels, G)==False:
# semi-sync의 coloring 된 node별로 udpate를 개별적으로 진행한다는 것.
for color, nodes in color_nodes_dict.items():
for node in nodes:
_update_node_label(node, G, node_labels)
# label propagation done.
################################################
for label in set(node_labels.values()):
yield set((x for x in node_labels if node_labels[x] == label))
############################################################
N = 500
G = nx.scale_free_graph(N, seed=0)
G = nx.Graph(G)
assert nx.is_connected(G)==True
# asynchronous LPA
async_time = time.time()
nx_async_LPA_comm = nx.algorithms.community.asyn_lpa_communities(G)
async_time -= time.time()
# networkx semi-synchronous LPA
semi_sync_time = time.time()
#nx_semi_sync_LPA_comm = nx.algorithms.community.label_propagation_communities(G)
nx_semi_sync_LPA_comm = label_propagation_communities(G)
semi_sync_time -= time.time()
# custom semi-synchronous LPA
custom_semi_sync_time = time.time()
custom_semi_sync_LPA_comm = custom_sync_LPA(G)
custom_semi_sync_time -= time.time()
print("==" * 30)
print("performance check")
print("--"*30)
computing_time_dict = {
'nx_____async_LPA': abs(async_time),
'nx_semi_sync_LPA': abs(semi_sync_time),
'cu_semi_sync_LPA': abs(custom_semi_sync_time)
}
partition_dict = {
'nx_____async_LPA': nx_async_LPA_comm,
'nx_semi_sync_LPA': nx_semi_sync_LPA_comm,
'cu_semi_sync_LPA': custom_semi_sync_LPA_comm
}
for LPA_func, partitions in partition_dict.items():
partitions = list(partitions)
# coverage
p_coverage = nx.algorithms.community.coverage(G, partitions)
# performance
p_performance = nx.algorithms.community.performance(G, partitions)
# modularity
p_modularity = nx.algorithms.community.modularity(G, partitions)
# print them.
print(f"== {LPA_func} :: COMPUTING TIIME - {computing_time_dict[LPA_func]:.6f} seconds")
print(f"coverage: {p_coverage: .5f}, performance: {p_performance: .5f}, modularity: {p_modularity: .5f}")
print("--"*30)
print("=="*30)
- 실행 결과는 다음과 같습니다.
- async보다 semi-sync가 훨씬 빠르고, 지표가 조금 안 좋은 것도 있지만, 큰 차이가 없습니다
- 다만, 제가 직접 구현한 코드가 더 빨라 보이는데, 이게 또, 저 둘만 따로 실행하면 그렇지도 않아요. 그냥 이전에 만들어둔 어떤 것들이 남아서 빠르게 쓰인것이 아닐까 싶어요.
============================================================
performance check
------------------------------------------------------------
== nx_____async_LPA :: COMPUTING TIIME - 0.082599 seconds
coverage: 0.54404, performance: 0.89583, modularity: 0.43450
------------------------------------------------------------
== nx_semi_sync_LPA :: COMPUTING TIIME - 0.000004 seconds
coverage: 0.46978, performance: 0.95052, modularity: 0.41918
------------------------------------------------------------
== cu_semi_sync_LPA :: COMPUTING TIIME - 0.000002 seconds
coverage: 0.46978, performance: 0.95052, modularity: 0.41918
------------------------------------------------------------
============================================================
wrap-up
- node coloring을 label propagation에 적용해보려는 생각을 어떻게 한걸까요? 저 아이디어를 착안한 것이 아주 대단하다고 생각되어요.
댓글남기기