tensorflow) softmax classifier
multi-class clasification
- 이전에 배웠던
logistic regression에서는 True/False 만 판별합니다. 그러나, 이런 binary classification보다는 multi-class classification이 훨씬, 유용하죠. - 이를 위해서
X*W+b를softmax function에 넣어서 계산해줍니다.X*W+b를 보통 logit이라고 합니다. 이후에도 나오니까, 기억해 두시면 좋을 것 같네요.
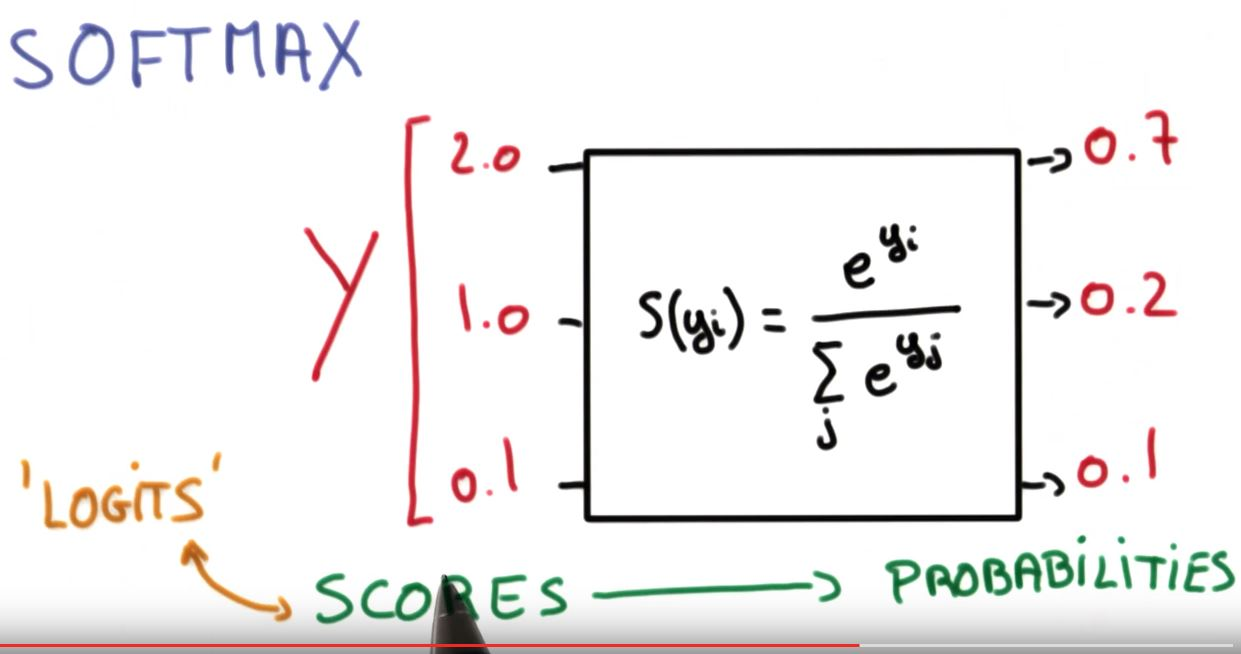
코드를 보자!!
- 그냥 코드를 보면서 얘기합시다. 일단 저는 multi-class 분류를 하기 위해서 제가 전에 만들어둔 데이터를 활용했습니다.
- 여러 가우시안 분포를 따르는 여러 가지 데이터를 생성하고, 어떤 분포를 따르는지 분류하도록 학습하려고 합니다.
import numpy as np
import tensorflow as tf
def normal_sampling(mu1, v1, mu2, v2, nrow):
x = np.random.normal(mu1, v1, nrow)
y = np.random.normal(mu2, v2, nrow)
return np.vstack([x,y])
"""
다양한 평균과 분산에 대해서 샘플링하여 쌓아줍니다.
np.hstack은 가로로 붙여줍니다. 그래서 마지막에 Transpose 했습니다.
"""
sample_size = 500
cluster_num = 3
x_data = np.hstack([
normal_sampling(0, 1, 0, 1, sample_size),
normal_sampling(2, 1, 2, 1, sample_size),
normal_sampling(3, 1, 7, 1, sample_size),
normal_sampling(8, 1, 4, 1, sample_size),
normal_sampling(6, 1, 5, 1, sample_size),
normal_sampling(6, 3, 0, 1, sample_size),
normal_sampling(0, 3, 6, 2, sample_size)
]).T
y_data = []
for i in range(0, x_data.shape[0]//sample_size):
y_data+=[i for j in range(0, sample_size)]
y_data = np.array(y_data)
tensorflow code
- 코드는 다음과 같습니다.
logit이 무엇인지 다시 기억해주시면 좋을 것 같구요.- cost function:
- logistic regression에서는 아래를 사용했습니다.
cost = -tf.reduce_mean(Y * tf.log(hypothesis) + (1 - Y) * tf.log(1 - hypothesis))`를 사용했습니다. - 여기서는 아래를 사용하는데, 별 차이 없다고 생각하셔도 됩니다. 다르면 페널티를 준다는 거니까요 결국. multi-label이니까 조금 더 고려할 것들이 많다, 정도로만 생각하시면 될것 같네요 하하핫
cost_i = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=Y_one_hot) cost = tf.reduce_mean(cost_i)
- logistic regression에서는 아래를 사용했습니다.
nb_features = 2
nb_classes = 7
X = tf.placeholder(tf.float32, [None, nb_features])
Y = tf.placeholder(tf.int32, [None]) # 0 ~ 6
Y_one_hot = tf.one_hot(Y, nb_classes)
W = tf.Variable(tf.random_normal([nb_features, nb_classes]), name='weight')
b = tf.Variable(tf.random_normal([nb_classes]), name='bias')
"""
logit으로 계산한 각 class 에 대한 값을 softmax function에 넘겨서 계산해줌
- exponential normalization? 같은 느낌이라고 생각하면 됨
"""
logits = tf.matmul(X, W) + b
hypothesis = tf.nn.softmax(logits)
# Cross entropy cost/loss
cost_i = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=Y_one_hot)
cost = tf.reduce_mean(cost_i)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
"""
- tf.argmax를 하면, axis를 축으로 변화하며 가장 큰 것의 index들을 리턴함
"""
prediction = tf.argmax(hypothesis, 1)
correct_prediction = tf.equal(prediction, tf.argmax(Y_one_hot, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# Launch graph
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(5000):
sess.run(optimizer, feed_dict={X: x_data, Y: y_data})
if step % 300 == 0:
loss, acc = sess.run([cost, accuracy], feed_dict={X: x_data, Y: y_data})
print("Step: {:5}\tLoss: {:.3f}\tAcc: {:.2%}".format(step, loss, acc))
# Let's see if we can predict
pred = sess.run(prediction, feed_dict={X: x_data})
# y_data: (N,1) = flatten => (N, ) matches pred.shape
"""
for p, y in zip(pred, y_data.flatten()):
if p != int(y):
print("[{}] Prediction: {} True Y: {}".format(p == int(y), p, int(y)))
"""
- 결과는 다음과 같습니다.
Step: 0 Loss: 7.286 Acc: 13.51%
Step: 300 Loss: 0.750 Acc: 79.66%
Step: 600 Loss: 0.669 Acc: 81.26%
Step: 900 Loss: 0.634 Acc: 81.49%
Step: 1200 Loss: 0.614 Acc: 81.74%
Step: 1500 Loss: 0.602 Acc: 81.89%
Step: 1800 Loss: 0.592 Acc: 82.14%
Step: 2100 Loss: 0.586 Acc: 82.14%
Step: 2400 Loss: 0.580 Acc: 82.09%
Step: 2700 Loss: 0.576 Acc: 82.09%
Step: 3000 Loss: 0.573 Acc: 82.20%
Step: 3300 Loss: 0.570 Acc: 82.26%
Step: 3600 Loss: 0.567 Acc: 82.34%
Step: 3900 Loss: 0.565 Acc: 82.20%
Step: 4200 Loss: 0.563 Acc: 82.09%
Step: 4500 Loss: 0.561 Acc: 82.17%
Step: 4800 Loss: 0.560 Acc: 82.14%
wrap-up
- 특별히 어려운 부분은 없었습니다. 다만,
- tensorflow를 값을 확인하면서 진행하는 것이 어렵고
- 매번 shape를 확인하면서 진행하는 것이 조금 불편하고
tf.cast,tf.argmax같은 tf operation을 사용하면서 진행해야 해서 덜 익숙한 부분이 있기는 하고- 역시, 다시
sklearn에 훨씬 쉬운 것들이 있는데, 내가 왜 이걸 해야 하나 라는 생각들은 들지만.
-
그래도, 의미가 있겠죠 하하하하
- 또한,
tensorflow에도 다양한 metric 들이 있을텐데, 일단 이 코드에서는 그러한 부분들이 활용되지 않았네요. 제가 이후에 사용해서 다시 또 말씀드리겠습니다.
reference
- https://docs.google.com/presentation/d/1FPcmOh_gmBw7uyOThFyKwdx7Ua2q8tX0kVFOSwI6kas/edit#slide=id.g1ed174f667_0_0
댓글남기기