slideshare) 딥러닝 큰 그림 그리기
- 슬라이드쉐어에 딥러닝에 대한 유용한 지식을 정리해둔 슬라이드가 있어서 제가 공부하면서 내용을 정리해두려고 합니다. 이것도, 아마 예전에 봤던 자료인데 또 까먹었어요 헤헤. 복습이 중요합니다.
뉴럴넷?
- 인공신경망이라고도 하는데, 간단하게 다음 그림처럼 생겼습니다.
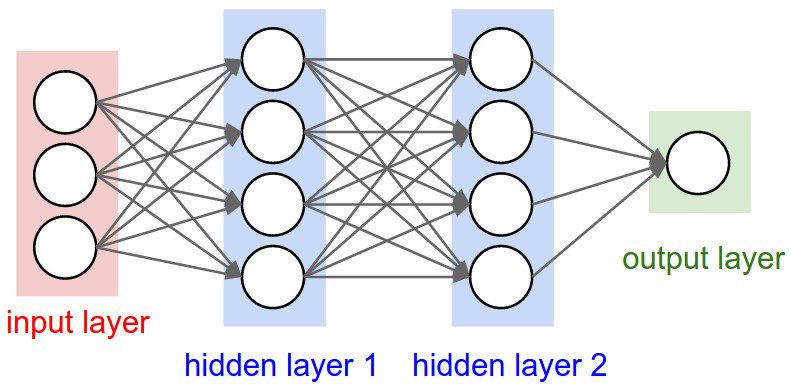
- 우리가 풀 문제를 예로 들어보면 “feature의 개수가 10개, output의 개수가 1개(binary classification or regression)”일 경우에, input_size: 10, output_size:1 이 됩니다.
- 우리가 조절할 수 있는 것은
hidden_layer_size인데, 이걸 몇 개로 해야 적합한지는, 여러 모델을 세우면서 직접 해봐야 알 수 있어요.
뉴럴넷의 세가지 문제
- 여기서는 뉴럴넷을 설계하고 돌려도, 문제가 발생한다고 합니다. 보통 다음 세 가지라고 한답니다.
- Underfitting: 트레인데이터에 적용해도 잘 못 맞추는 경우
- Slow Learning: 학습이 너무너무 느리거나.
- Overfitting: 트레이닝데이터에 너무 잘 맞는데, 테스트 데이터에 적용해보면 너무 문제가 많은 경우.
- 이 각각의 문제에 대해서 하나씩 어떻게 해결할 수 있는지를 정리해볼게요.
Underfitting
- 뉴럴넷의 구조는 사실 간단합니다. 레이어를 여러 개 쌓는 다는 것이 사실 다죠. output layer에서 발생한 차이(예를 들어, 1을 예측해야 하는데, 현재는 0이 계산된다거나)를 미분하여 앞 layer로 넘기면서 weight를 변화시킵니다. 이걸 backpropagation, 역전파라고 해요.
- layer의 개수가 적으면 아무 문제가 없지만, layer의 개수가 적어지면, 문제가 커집니다. 특히 sigmoid의 경우 아래 처럼 일정 값을 넘거나, 일정값보다 작은 경우에는 기울기가 존재하지 않습니다.
- layer 개수가 많고, 모두 sigmoid로 되어 있을 경우에는 앞으로 넘겨지는 값이 0에 가까워지기 때문에, 제대로 된 학습이 어렵죠.
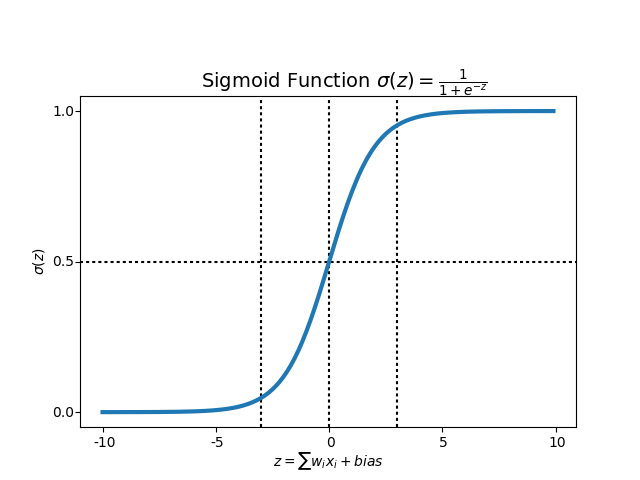
- backpropagation의 결과가 앞쪽의 layer까지 잘 전달이 되지 않는 경우를 vanishing gradient라고 합니다.

Use ReLU
- 어떻게 해결하느냐, ReLU를 써서 해결합니다. ReLU는 0 이상의 값에서 모두 미분값이 존재하거든요. 따라서 이 아이를 쓰면, 끝까지 backpropagation이 잘 됩니다.
Slow learning
- 간단히 말해서, 뉴럴넷을 학습한다는 것은 cost function을 최소화하는 weight를 찾는 것이죠. 이를 위해서, weight를 업데이트해야 하는데, 이는 두 가지 문제로 변경됩니다. 이 두 가지 문제를 각각 풀어봅니다.
- 어떤 방향으로 가야 하는가?
- 방향이 결정되면, 그 방향으로 얼마나 움직인 다음 다시 방향을 확인해야 하나?
어떤 방향으로?: Gradient Descent
- 현재 뉴럴넷이 weight를 최적화하는 방법은 Gradient Descent.
- Gradient Descent: cost function의 현재 가중치(weight)에서의 기울기 를 구해서 weight를 업데이트시켜 나가는 방식
- 어렵게 읽힐 수 있지만, 포물선에서 최대/최소 값을 찾는 것과 같습니다. 단 한번에 찾는 것이 아니고, 현재 값에서 (최대/최소)값이 있다고 생각되는 방향으로 한 발짝씩(learning-rate) 움직이는 것이죠.
- 그런데, 이 Gradient Descent를 계산해서 weight를 업데이트할 때, 보통 현재 데이터를 모두 넣어서 계산합니다만, 내가 가지고 있는 데이터가 만약 100억 개라고 해보죠, 단 한번의 weight 업데이트를 위해서 모든 데이터를 다 때려넣어서 cost 를 계산하고, 거기서 아주 쪼끄만 learning rate만큼 움직이는 것을 반복한다는 것이, 자연스러운 일일까요?
- 이걸 해결하기 위해서 stochastic Graident Descent가 나왔습니다.
GD vs. SGD
- 아래 그림이 잘 설명하고 있습니다만, 전체 데이터를 다 활용하여 cost를 계산하고, 그 방향으로 weight를 움직이는 Gradient Descent의 경우 매 step이 매우 효율적으로 움직이는 반면, stochastic GD는 움직임이 들쭉들쭉 한 것을 알 수 있습니다.
- 그래도, contour 라인을 보면 점점 cost를 줄이는 방향으로 움직이고 있는 것은 둘다 같습니다. 저는 그냥 SGD를 일단 써보고, 만약 잘 되면 나중에 GD로 변형해보면서 해보는 게 나을 것 같네요.
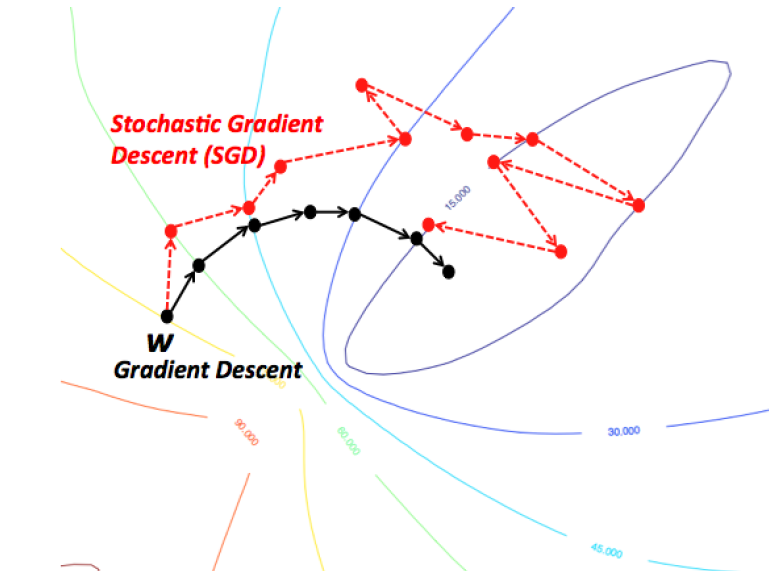
- 어쨌든, Gradient Descent를 사용하면 어떤 방향으로 가야할지는 결정됩니다. 자 이제,
그 방향으로 얼마나 가나요?: learning rate
- 얼마나 가야할까요? 아래 그림을 보시면, 한 걸음씩 걸으면 너무 느리고(보수!), 너무 많이 걸으면 최적값을 지나치는 문제가 발생합니다. 사실 현실에서, “지금 당신이 이쯤 와 있어요”라는 것을 알려주는 네비게이션이 있으면 좋겠지만, 그런거 없어요. 결국 learning rate도 알아서 조절하면서 진행하는 방법 밖에 없습니다.

쫌 알아서 조절해줘요!
- 네, 세상에는 저 같은 알못들이 많고, 이것도 저것도 다 편하게 좀 해주세요! 라는 사람이 많기 때문에, 많은 optimizer들이 나와 있습니다. 그냥, 결론은 잘 모르면 Adam을 씁시다.

Overfitting
- 이 문제는, 앞서 제시한 문제들보다는 사실 작은 문제라고 생각합니다. 학습할때, 일단 overfitting이라고 되는 게 매우 중요합니다. overfitting되었다는 이야기는, 최소한 현재 데이터의 주요한 피쳐들을 모두 찾아내었다는 거거든요. 트레이닝 데이터의 특징조차 발견하지 못하는 clf들이 많습니다.
-
또한 오버피팅은 세상에 존재하는 모든 데이터를 획득할 수 없는 모든 데이터 사이언티스트들의 숙명과도 같습니다. 예를 들어서, 제가 “고양이가 있는지 없는지”를 판별하는 분류기를 만든다고 합시다. 그런데 제가 세상에 존재하는 모든 고양이 사진을 다 가지고 있을 수는 없어요. 우연하게 “저한테는 점박이 고양이 사진들만 있는데”, 저는 이 사진들로, “어떤 고양이 사진을 가지고와도 대충 맞춰주는 분류기”를 만들고 싶어요. 이럴때, overfitting해주는 기술이 필요합니다.
- 정리하자면, ‘점박이가 있는 고양이를 찾아주는 분류기’ => ‘고양이를 찾아주는 분류기’로 generalization해주는 것이죠.
뉴럴넷을 다시 생각해봅시다.
- 뉴럴넷을 그냥 막 쌓아가면서(사이즈만 조절해가면서) 돌려서 그런데, 사실 뉴럴넷의 각 node가 무엇을 의미하는 것인지를 다시 확인할 필요가 있습니다. input vector에 weight를 곱하고, activation function을 먹여서 나온 값들이 바로 다음 레이어의 값이죠. 마치, 이건 feature engineering으로 보이기도 합니다.
- 다시 돌아와서, 뉴럴넷의 각 노드는 원래의 값들을 잘 조절해준, 새로운 feature라고 해석할 수도 있습니다. 만약 학습된 데이터가 고양이 이미지라면, 다음처럼 해석될 수 있는 것이죠.
- node1: 고양이에게 귀가 있는지 판별
- node2: 고양이에게 눈이 있는지 판별
- node3: 고양이에게 점박이 무늬가 있는지 판별
-
즉, 개별 노드들은 고양이가 가지고 있는 특성을 판별합니다. 마지막 레이어 에서는 이 피쳐들을 종합해서 결정을 내리게 되죠.
- 네, 그래서 generalization을 해준다는 이야기는, 이 feature들을 조금 덜 민감하게 만들어준다는 말과 같습니다.
DropOut
- 이게 좀 웃기는 이야긴데..DropOut은 학습 사이사이에 특정 노드는 학습이 되지 않도록(backpropagation 결과가 적용되지 않도록)하는 것을 말합니다.
- 어떤 사진에서는 ‘귀가 있는 feature’를 학습하지 않고, 어떤 사진에서는 ‘점박이’를 학습하지 않습니다.
- 이렇게 반복하다보면, 결과적으로는 대부분의 사진에 있는 ‘일반적인 특징’들만이 남게 되고, 결국 generalization을 달성하게 되는 것이죠.
딥러닝 아키텍쳐
- 데이터는 두 가지로 분류됩니다.
- 스냅샷 성 데이터: 사진, 이미지 등
- 시퀀스 성 데이터: 음성, 언어, 시계열 데이터 등
- 각각은 또 서로 다른 딥러닝 아키텍쳐를 필요로 하는데
- 스냅샷 성 데이터 ==> CNN
- 시퀀스 성 데이터 ==> RNN, LSTM
wrap-up
- 그러니까, 간단하게 정리를 해보면 다음과 같습니다.
- activation function: sigmoid 말고 relu 쓰세요.
- optimizer: Adam 쓰세요
- Dropout: 왠지 overfitting된 것 같으면 dropout을 쓰세요
- 이미지 데이터는 CNN, 시퀀스데이터는 RNN
댓글남기기