gensim을 이용하여 doc2vec 이용하기.
intro.
- 저는 최근에, 텍스트를 효과적으로 처리하고, 특히, 유의미한 정보를 추출하는 작업을 수행하고 있습니다. 특히, 적합한 데이터를 찾는 측면에서 이 작업을 수행하고 있습니다.
- 그 과정에서, 몇 가지 유용한 자연어 처리 기법을 찾고있고, 그중에서 doc2vec이 유용하게 사용될 수 있는 것 같습니다.
what is doc2vec
- 2vec의 의미는 “의미를 가진 어떤 것”을 “numerical vector”로 표현했다는 것을 의미합니다.
- 따라서, doc2vec 또한 Document 2 Vector를 의미하는 것이죠. 결국 word2vec과 유사한 방법인 것인데, 여기서 어떻게 임베딩하느냐, 즉, 무엇이 인풋이고, 무엇이 아웃풋인지만 정리되면 되는 것 같습니다. <>
-
이 블로그에서 내용이 비교적 잘 정리되어 있는 것 같습니다.
- 요약하자면,
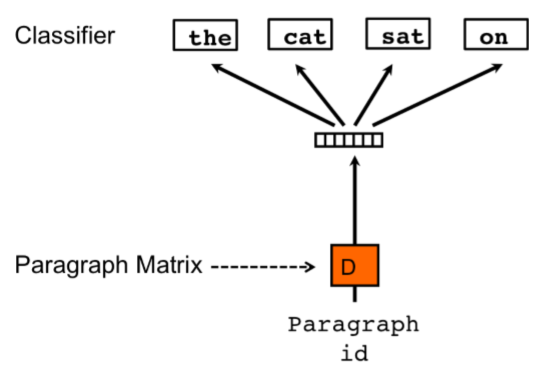
PV-DM(Paragraph Vector with Distributed Memory)
- paragraph vector를 input으로 활용하며, 동시에 해당 paragraph에 포함되어 있는 단어들을 window만큼 옮기면서, 다음 단어를 예측하는 방식으로 학습함.
- input: paragraph vector와 정해진 길이(window)의 단어
- output: 앞서 나온 길이(window)의 단어의 뒤 단어
- 여기서 “paragraph vector”가 해당 문서의 모든 input으로 들어가며, 일종의 메모리로서의 역할을 해주고 있다고 할 수 있습니다. 다르게 표현하면, 하나의 중심축을 잡아주고 있다고도 할 수 있겠네요. 그래서 distributed memory인가 봅니다.

PV-DBOW(Paragraph Vector with Distributed Bag Of Words)
- PV-DBOW의 경우 비교적 간단한 편인데, paragraph vector를 input으로 넣고, 결과는 해당 paragraph에 포함되어 있는 단어들이 되죠.
- 여기서도 아마 window를 조절할 수 있을 것으로 보이네요.
how to use it: 그래서, 어떻게 쓸 수 있나.
- 솔직히 저는, 엔지니어고, 어떻게 쓸 수 있고, 어디에 사용할 수 있고, 어떤 효과가 있는지에 대해서만 더 관심이 있습니다.
- 그래서, 일단 이 차이는 알겠고, 한번 쓰면서 보도록 하겠습니다.
just do it.
- 사용법과 사용법에 대한 설명은 아래 코드에 정리하였습니다.
from sklearn.cluster import KMeans
# common_text에는 파싱된 워드 리스트들이 들어가 있음.
from gensim.test.utils import common_texts
# Doc2Vec이 우리가 텍스트를 사용해서 학습되는 모델(뉴럴넷)이고
# TaggedDocument가 넘겨주는 텍스트들.
# 여기서, corpus와 ID들을 함께 넘겨줘야 하는데, 여기서 ID는 tag와 같은 말임
# Q: 여기서, 여러 tag를 함께 넘겨준 다음, 적합한 태그를 찾아주는 방식으로도 처리할 수 있는지 파악하는 것이 필요함.
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
# TaggedDocument는 해당 corpus의 id를 함께 넘겨주는 것을 말합니다.
# 아래 코드에서 doc에는 단어의 묶음이, tags에는 해당 문서를 표현하는 태그가 들어가게 됨.
# 흠, 그렇다면, 이 태그에 고유 id가 아닌 다른 것을 넣어주면 현재 문서에 맞는 tag를 찾아주기도 하나?
# 이렇게 할 경우, words에는 문서를, tags에는 키워드를 넣고, words에서 tags를 예측하는 짓을 할 수도 있지 않을까?
common_texts_and_tags = [
(text, [f"str_{i}",]) for i, text in enumerate(common_texts)
]
print("##"*20)
print("tags and its texts")
print("##"*20)
for text, tags in common_texts_and_tags:
print(f"tags: {tags}, text: {text}")
# text: 단어별로 분할되어 있는 리스트
# tags: 해당 문서를 의미하는 태그. 여기서, tags를 unique id로 넣기는 했는데, 그렇지 않게 넣어서 학습시키는 것도 가능할 것으로 보임.
TRAIN_documents = [TaggedDocument(words=text, tags=tags) for text, tags in common_texts_and_tags]
# training.
# 여러 Parameter들을 사용하여 튜닝할 수 있음.
model = Doc2Vec(TRAIN_documents, vector_size=5, window=3, epochs=40, min_count=0, workers=4)
print("##"*20)
print("Accessing Document vector")
print("##"*20)
# document의 vector를 구하는 방법은, 기 학습된 docvec을 가져오거나, 해당 단어를 넣고 다시 예측하는 것.
# 단, tag로 접근이 가능할 뿐, 학습한 doc를 그대로 가져오는 것은 어려운 것으로 보임.
# 또한, 여기서, 학습된 vector와 inferring한 vector가 미묘하게 다른데, 이것은 현재 train set이 적어서 그런 것으로 보임.
for text, tags in common_texts_and_tags:
trained_doc_vec = model.docvecs[tags[0]]
inferred_doc_vec = model.infer_vector(text)
print(f"tags: {tags}, text: {text}")
print(f"trained_doc_vec: {trained_doc_vec}")
print(f"inferred_doc_vec: {inferred_doc_vec}")
print("--"*20)
print("##"*20)
print("predicting Document vector")
print("##"*20)
new_documents = [
["computer", "interface"],
["I", "am", "a", "boy"]
]
# predict training set with its infering vector)
for text in new_documents:
inferred_v = model.infer_vector(text)
# 현재 doc를 모델을 사용하여 벡터화할때의 값
print(f"vector of {text}: {inferred_v}")
# 기학습된 문서중에서 현재 벡터와 가장 유사한 벡터를 가지는 문서를 topn만큼 추출합니다.
most_similar_docs = model.docvecs.most_similar([inferred_v], topn=3)
# index와 그 유사도를 함께 보여줍니다.
# index(tag)가 아닌 문서를 바로 보여주기는 어려운 것 같고,
for index, similarity in most_similar_docs:
print(f"{index}, similarity: {similarity}")
#print(most_similar_docs)
print("=="*20)
# document clustering
print("##"*30)
print("K-Means Clustering")
print("##"*30)
Clustering_Method = KMeans(n_clusters=2, random_state=0)
X = model.docvecs.vectors_docs # document vector 전체를 가져옴.
Clustering_Method.fit(X)# fitting
# 결과를 보면 알겠지만, 생각보다 클러스터링이 잘 되지 않음.
# 일단은 이것 또한 트레이닝 셋이 적어서 그런 것으로 보임.
cluster_dict = {i:[] for i in range(0, 2)}
for text_tags, label in zip(common_texts_and_tags, Clustering_Method.labels_):
text, tags = text_tags
cluster_dict[label].append(text)
for label, lst in cluster_dict.items():
print(f"Cluster {label}")
for x in lst:
print(x)
print("--"*30)
print("##"*20)
- 실행 결과는 다음과 같습니다.
########################################
tags and its texts
########################################
tags: ['str_0'], text: ['human', 'interface', 'computer']
tags: ['str_1'], text: ['survey', 'user', 'computer', 'system', 'response', 'time']
tags: ['str_2'], text: ['eps', 'user', 'interface', 'system']
tags: ['str_3'], text: ['system', 'human', 'system', 'eps']
tags: ['str_4'], text: ['user', 'response', 'time']
tags: ['str_5'], text: ['trees']
tags: ['str_6'], text: ['graph', 'trees']
tags: ['str_7'], text: ['graph', 'minors', 'trees']
tags: ['str_8'], text: ['graph', 'minors', 'survey']
########################################
Accessing Document vector
########################################
tags: ['str_0'], text: ['human', 'interface', 'computer']
trained_doc_vec: [-0.05239485 0.05015887 -0.04648273 -0.02516159 -0.05178743]
inferred_doc_vec: [ 0.02042231 -0.08833984 0.08115575 -0.01269518 0.09916037]
----------------------------------------
tags: ['str_1'], text: ['survey', 'user', 'computer', 'system', 'response', 'time']
trained_doc_vec: [ 0.09714173 -0.00755139 0.01935733 -0.03975544 0.07477333]
inferred_doc_vec: [ 0.09293693 0.06929842 -0.02899511 -0.02760071 -0.02961491]
----------------------------------------
tags: ['str_2'], text: ['eps', 'user', 'interface', 'system']
trained_doc_vec: [-0.06118867 -0.07201414 -0.02389454 0.09447891 -0.09430525]
inferred_doc_vec: [-0.07778556 -0.07527453 -0.02989961 0.05037848 -0.07642413]
----------------------------------------
tags: ['str_3'], text: ['system', 'human', 'system', 'eps']
trained_doc_vec: [ 0.0925656 -0.04927092 -0.02840239 -0.07252068 -0.03123596]
inferred_doc_vec: [-0.06030891 0.09824309 0.04839226 -0.03875912 -0.04739589]
----------------------------------------
tags: ['str_4'], text: ['user', 'response', 'time']
trained_doc_vec: [ 0.01065322 -0.09985279 0.04406673 0.07354512 -0.08171134]
inferred_doc_vec: [ 0.08589073 0.01462008 -0.01508138 -0.01833059 0.07774612]
----------------------------------------
tags: ['str_5'], text: ['trees']
trained_doc_vec: [ 0.04365815 -0.02981959 -0.06905553 0.03499922 0.08785328]
inferred_doc_vec: [-0.0137947 0.00845423 -0.02949649 0.04813654 0.03203766]
----------------------------------------
tags: ['str_6'], text: ['graph', 'trees']
trained_doc_vec: [ 0.03264341 -0.09570815 0.06430981 0.08152123 0.0917829 ]
inferred_doc_vec: [ 0.00179712 -0.08315558 0.05591539 0.09536273 -0.05672819]
----------------------------------------
tags: ['str_7'], text: ['graph', 'minors', 'trees']
trained_doc_vec: [-0.08245 0.03346359 0.04372411 0.08866451 -0.01322902]
inferred_doc_vec: [ 0.06723227 0.03251187 0.02720621 -0.04213455 0.04514208]
----------------------------------------
tags: ['str_8'], text: ['graph', 'minors', 'survey']
trained_doc_vec: [-0.05334936 0.08100092 -0.06138805 0.02021051 0.06548116]
inferred_doc_vec: [-0.04899735 0.07465426 -0.05100149 -0.03618782 0.04262831]
----------------------------------------
########################################
predicting Document vector
########################################
vector of ['computer', 'interface']: [-0.03726221 -0.02957473 -0.03790623 -0.0621733 -0.08705801]
str_0, similarity: 0.6511919498443604
str_3, similarity: 0.38194623589515686
str_2, similarity: 0.376160204410553
========================================
vector of ['I', 'am', 'a', 'boy']: [ 0.07655911 -0.09196001 0.03480676 0.08846788 0.08596554]
str_6, similarity: 0.9521167278289795
str_5, similarity: 0.6360737085342407
str_1, similarity: 0.5118666887283325
========================================
############################################################
K-Means Clustering
############################################################
Cluster 0
['survey', 'user', 'computer', 'system', 'response', 'time']
['system', 'human', 'system', 'eps']
['trees']
['graph', 'trees']
------------------------------------------------------------
Cluster 1
['human', 'interface', 'computer']
['eps', 'user', 'interface', 'system']
['user', 'response', 'time']
['graph', 'minors', 'trees']
['graph', 'minors', 'survey']
------------------------------------------------------------
########################################
I/O
- 한번 학습을 해놓으면 나중에 덜 귀찮을 수 있습니다. 나중에 이미 학습된 것을 그대로 가져와서 사용하기 위해서는 다음 코드를 사용하면 좋습니다.
# store the model to mmap-able files
model.save('/tmp/my_model.doc2vec')
# load the model back
model_loaded = Doc2Vec.load('/tmp/my_model.doc2vec')
- 다만, 생각보다 이게 잘 안되는 경우가 있습니다. 이럴 때는 그냥
pickle을 사용하도록 합시다.
wrap-up
- 우선, 아쉽게도, 적은 training 세트로는 doc2vec의 유용성을 파악하기 어려웠습니다. 이후 많은 데이터셋을 대상으로 파라미터 등을 변경하면서 적용하면 충분히 유효한 효과를 파악할 수 있지 않을까 생각합니다만, 모르는 일이죠.
- 그러함에도, 현재 알게된 doc2vec을 이용해서 쓸 수 있는 기법은 다음정도가 있을 것 같습니다.
- Document Clustering
- 말 그대로 문서를 벡터화하는 것이기 때문에, 비슷한 의미를 가진 클러스터링을 묶어낼 수 있습니다.
- 특히, TF, TF-IDF등과 다르게, 의미를 벡터화할 수 있기 때문에 보다 유용성이 있지 않을까 생각해봅니다.
- Find similar document or tags
- 새로운 문서가 들어왔을 때, 해당 문서와 제일 유사한 문서 혹은 태그를 뽑아낼 수 있습니다.
- 현재 학습방법을 보면, 학습데이터를 넘길 때
TaggedDocument라는 형태로 넘기는 것을 알 수 있습니다. 이는 (Word_set,Tag_set)를 함께 넘기는 식인데, 결국 서로 다른 데이터간의 matching을 이를 통해 알 수 있는 것이죠. - 즉, 우리가 흔히 아는 인스타그램을 생각해보면, 각 글은 (
text,tags)의 형태로 존재하는 것을 알 수 있습니다. 즉, 이를 그대로 학습시킬 수 있지 않을까? 라고 생각해봅니다.
- Document Clustering
- differ inferred vector
- 몇 번 돌려보면 알겠지만, 도큐먼트에 대한 벡터 값이 매번 조금씩 달라집니다.
- 이를 좀 더 정확하게 표현하려면,
inferred_vector의 파라미터, 특히 epoch를 높여서 처리하면 좀 나아지기는 합니다. - 뭐, 매우 정확하게 할게 아니라면, 적당히 해도 적당히 잘 나와요. 비슷비슷하게는 나오니까요 하하
댓글남기기