gensim - Tutorial - Word Mover Distance(WMD)
3 분 소요
Intro.
- Word Mover’s Distance(WMD)는 “사용자가 제출한 query에 대해서 가장 관련있는(relevant) 문서들을 줄수 있도록 해주는, 머신러닝 분야의 유망한 기술”입니다.
- 이 tutorial에서는 두 document에 대해서 WMD Distance를 측정하는 방법을 소개하고 게산해본다.
Word Mover Distance(WMD) Basics.
- WMD는 서로 다른 두 문서에 대해서 “공통된 의미를 가지고 있지 않을 때에도” 의미를 고려하여(in a meaningful way) “거리(distance)”를 평가하도록 해주비나. 그리고 이 과정에서 각 문서의 단어들의 위치는 Word2Vec으로 위치시키죠.
- 즉, 이미 학습된 Word2Vec이 있을 때, 이를 사용하여 두 문장들간의 거리를 효과적으로 측정하는 방법을 말합니다. 이 때, 반드시 동일한 단어가 존재하지 않더라도, 비슷한 의미의 단어가 두 document에 존재한다면(Word2vec 상에서 거리적으로 유사한 곳에 위치한 단어들이 있다면), 알아서 이를 바탕으로 두 문장간의 거리를 측정해주죠.
- 다음 그림으로 보시면 좀 더 명확하게 이해되실 수 있습니다. 각 문장(Document)에 위치한 단어(word)의 거리를 고려하여 두 문장간의 거리를 계산해준다, 라는 것이죠.
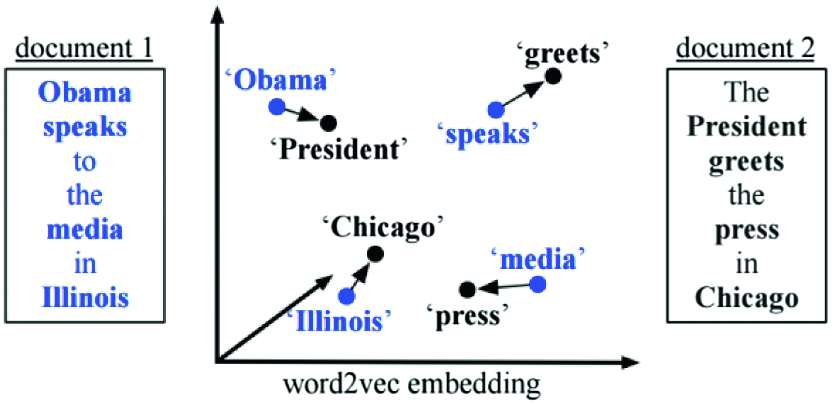
Computing WMD
- 사용해보겠습니다. 바닥부터 하나하나 계산하는 방법도 있지만, 거인의 어깨에 허락받지 않고 올라타는 저는
gensim을 사용해서 결과가 잘 나오는지만 파악해보기로 합니다.
LOAD trained-word2vec.
- 우선, Word2Vec model을 가져옵니다. WMD는 각 단어의 vector를 알고 있다는 가정 하에서 시작됩니다. 그 다음에야 거리를 측정할 수 있으니까요.
- 만약 corpus가 있다면 직접 학습하는 것도 가능하지만, 저는 이미 학습된 것을 가져왔습니다. 제가 가져온 모델은 GoogleNews-vectors에서 상대적으로 빈번하게 쓰이지 않는 단어들을 제외한, GoogleNews-vectors-negative300-SLIM입니다.
import gensim
import time
from nltk.corpus import stopwords
if True:
# LOAD Word2Vec model
# 내 컴퓨터에서는 읽을 때, 약 10초가 걸림.
googleNews_filepath = "GoogleNews-vectors-negative300-SLIM.bin"
start_time = time.time()
print(f"== LOAD {googleNews_filepath} as word2vec model START")
GoogleSlimModel = gensim.models.keyedvectors.KeyedVectors.load_word2vec_format(
googleNews_filepath, binary=True
)
# assert 에 문제가 있으며 ㄴ제대로 읽혀지지 않은 것임.
assert GoogleSlimModel.wv.most_similar(positive=['car', 'minivan'], topn=5) == [('SUV', 0.8532191514968872), (
'vehicle', 0.8175784349441528), ('Jeep', 0.7567334175109863), ('sedan', 0.7446292042732239), ('truck', 0.7273114919662476)]
print(f"== LOAD {googleNews_filepath} as word2vec model COMPLETE, {time.time() - start_time}")
print("=="*30)
COMPUTE WMD for sentences
def doc_preprocess(sentence):
"""
`sentence`를 가져와서, 적합한 word만을 남겨서 리턴
"""
stop_words = stopwords.words('english')
word_lst = [w for w in sentence.lower().split() if w not in stop_words]
return word_lst
sentence_obama = doc_preprocess('Obama speaks to the media in Illinois')
sentence_president = doc_preprocess('The president greets the press in Chicago')
sentence_orange = doc_preprocess('Oranges are my favorite fruit')
# sentence_obama, sentence_president의 거리.
distance = GoogleSlimModel.wmdistance(sentence_obama, sentence_president)
print(f"distance = {distance}")
# sentence_obama, sentence_orange의 거리.
distance = GoogleSlimModel.wmdistance(sentence_obama, sentence_orange)
print(f"distance = {distance}")
distance = 1.0174646259300113
distance = 1.3663488311444436
Error: No module named pyemd
- 위의 코드를 진행할 때, 다음과 같은 에러 메세지가 발생할 수 있습니다. 즉,
pyemd라는 라이브러리가 설치되어 있지 않다는 말이죠.
ModuleNotFoundError: No module named 'pyemd'
- pyemd는 python에서 Earth-Mover-Distance를 지원하는 라이브러리입니다. 그리고 이 아이는 “서로 다른 확률 분포간의 거리를 측정하는 방법”을 의미하죠. 우리도 각 문장의 word 분포(혹은 histogram)들 간의 거리를 측정하며, 이 때
gensim이 pyemd를 사용하고 있습니다. 따라서 그냥 아래와 같이 설치해주면 됩니다.
wrap-up
- 사실 이미 Doc2Vec을 알고 계신다면, “그 방법이 더 효과적인거 아니냐?”라고 말할 수도 있습니다. 그리고 사실 이미 우리에게 corpus가 존재한다면 거기서 바로 doc2vec을 학습시키는 것이 효과적일 수도 있죠.
- 다만, 우리에게 word2vec밖에 없는 경우에는 WMD를 이용해서 문서들간의 거리를 측정할 수 있겠습니다. 그리고 Doc2Vec과 비교하면 계산 속도 면에서 훨씬 이점이 있겠죠.
reference
raw-code
import gensim
import time
from nltk.corpus import stopwords
if True:
# LOAD Word2Vec model
# 내 컴퓨터에서는 읽을 때, 약 10초가 걸림.
googleNews_filepath = "GoogleNews-vectors-negative300-SLIM.bin"
start_time = time.time()
print(f"== LOAD {googleNews_filepath} as word2vec model START")
GoogleSlimModel = gensim.models.keyedvectors.KeyedVectors.load_word2vec_format(
googleNews_filepath, binary=True
)
# assert 에 문제가 있으며 ㄴ제대로 읽혀지지 않은 것임.
assert GoogleSlimModel.wv.most_similar(positive=['car', 'minivan'], topn=5) == [('SUV', 0.8532191514968872), (
'vehicle', 0.8175784349441528), ('Jeep', 0.7567334175109863), ('sedan', 0.7446292042732239), ('truck', 0.7273114919662476)]
print(f"== LOAD {googleNews_filepath} as word2vec model COMPLETE, {time.time() - start_time}")
print("=="*30)
def doc_preprocess(sentence):
"""
`sentence`를 가져와서, 적합한 word만을 남겨서 리턴
"""
stop_words = stopwords.words('english')
word_lst = [w for w in sentence.lower().split() if w not in stop_words]
return word_lst
sentence_obama = doc_preprocess('Obama speaks to the media in Illinois')
sentence_president = doc_preprocess('The president greets the press in Chicago')
sentence_orange = doc_preprocess('Oranges are my favorite fruit')
# sentence_obama, sentence_president의 거리.
distance = GoogleSlimModel.wmdistance(sentence_obama, sentence_president)
print(f"distance = {distance}")
# sentence_obama, sentence_orange의 거리.
distance = GoogleSlimModel.wmdistance(sentence_obama, sentence_orange)
print(f"distance = {distance}")
댓글남기기