gensim - tutorial - Doc2Vec - TaggedDocuments
3-line summary
- gensim에서 Doc2vec을 학습하기 위해서는 각 문서들을
(words, tags)의 형태로 표현하고 학습함. - 이 때
tags는 반드시 unique document_ID이어야 하는 것은 아니며, 인스타그램 태그처럼 여러 개를 동시에 넣을 수도 있습니다.
Doc2vec
- Doc2vec은 word2vec을 확장한 방법론입니다. 개념적으로 보면, ‘word’를 벡터로 표현하는 것이 가능했다면, ‘word’의 합인 document를 벡터로 표현하는 것 또한 가능하겠죠. 아주 단순히 말하면, doc2vec 내에 존재하는 모든 word의 벡터의 평균을 구하는 것도 doc2vec의 방법 중 하나가 되긴 할 겁니다(물론, 얼마나 뛰어난 퍼포먼스를 보여줄지는 모르지만요).
- 결국 doc2vec은 내부 word vector들을 사용해서 가장 효과적으로 document를 벡터로 표현해주는 방법을 말합니다. 다만, 그 과정은 다음의 그림을 따르죠.

Doc2Vec and unique document ID
- 그림을 보니까 어떤가요? 사실 상 word2vec과 큰 차이가 없는 것으로 보이지 않나요? 그냥, 원래 word vector를 input으로 넣어주는 것처럼, 그냥 document에 대한 vector를 추가해준 것 뿐입니다.
- 가령 우리에게 [I, am, a, boy]라는 document가 있다면, word2vec에서는
(am, a) ==> (I)와 같은 식으로 넣어주죠. - 하지만, doc2vec에서는
(am, a, document_1) ==> (I)와 같은 식으로document_1이라는 word를 새롭게 추가해주는 것입니다. 즉, 하나의 document를 학습할 때, 이 document로부터 나온 것에 대한 특성을 부여하기 위한, 새로운 키워드를 매번 넣어준다, 라는 것이죠. - 그리고, 일반적으로는 “각 document에 대한 unique ID”를 넣어줍니다. 그리고, 이는 각 document간에 연관성이 없다, 라는 것을 가정하고 있죠. 물론 그러함에도 중복되는 word들이 있으면 자연히, 가깝게 학습되기는 하겠죠.
- 이를 word2vec과 비교해 보겠습니다. word2vec에서 보면 초기에 ‘research’와 ‘researches’를 아예 다른 vector라고 가정하고 학습합니다. 사실상 형태적으로는 같지만, 출발점에서 다르다고 가정하는 것이죠. 다만, 진행되면서, 두 단어의 앞뒤 맥락(앞 뒤 단어들)이 비슷하다면 결과적으로는 비슷하게 나오겠지만요.
- 이처럼, 모든 document에 대해서 서로 다른 unique ID를 붙여준다는 것은 그 document들간에 “아무 관련성이 없다”라는 것을 가정한다는 것이죠. 물론, 이는 좋은 출발점입니다. 그걸 모르니까, 그걸 document를 vector로 학습을 시키는 것이니까요.
gensim.Doc2vec
- 그럼, 이제
gensim의 doc2vec을 사용해서 학습을 진행해 보겠습니다. - 다만 학습 전에 한 가지 전처리할 것이 필요한데, document를
gensim.TaggedDocument(words=words, tags=tags)로 변환해줘야 합니다.
gensim.TaggedDocument
- 변환은 어렵지 않습니다.
TaggedDocument(words=s, tags=tags)를 사용하고,words는 해당 document를 word 단위로 쪼개어 준 것이죠. 그리고,tags는 아까 말한 각 document에 대한 ID를 말하는데, 말 그대로, tag, 혹은 논문에 들어가는 키워드들 이라고 말해도 상관없습니다.
from gensim.models.doc2vec import TaggedDocument
sentences = [
"He is a boy", "He is a man", "She is a girl"
]
sentences = [s.lower().strip().split(" ") for s in sentences]
# 각 document들이 모두 서로 다르다고 가정하므로 unique_int_id를 설정해줌.
taggedDocs = [TaggedDocument(words=s, tags=[f"Document_{i}"]) for i, s in enumrate(sentences)]
- 그리고, 저는 여기서 궁금증이 생겼습니다. 거의 대부분의 문서들과 블로그들에서 Doc2vec을 사용하기 위해
TaggedDocument를 사용할 때,tags를 그냥 unique_id 하나씩으로만 넘기는 것을 알 수 있습니다. 그런데, 사실 저 아이는 여러 값을 동시에 받을 수가 있거든요. 즉, 정말 인스타그램 태그나, 논문의 키워드들처럼 여러 개를 동시에 넘길 수 있다는 것이죠.
TaggedDocument with multiple Tags
- 그래서, 저는 직접 여러 중복되는 tag를 넘겨서 학습을 해보기로 했습니다. 그리고 그 차이를 파악해보려고 했죠. data는 그냥 간단한 3개의 문장으로 처리하기로 했습니다.
sentences = [
"He is a boy", "He is a man", "She is a girl"
]
sentences = [s.lower().strip().split(" ") for s in sentences]
- 그리고, 아래처럼 document별로 tag를 다양한 방식으로 달기로 했죠.
SAME tags: 모든 문서에 동일한 document ID를 주는 것이므로, document들이 매우 유사하다고 생각하는 경우DIFF tags: 모든 문서에 다른 document ID를 주는 것이므로, document들이 모두 다르다고 생각하는 경우RICH tags: 모든 문서에 동일한 document ID를 여러 개 주는 경우
# 각 Document별로 다양한 방식으로 TAG를 설정해줌
tags_dict = {
"SAME tags": [[1] for s in sentences],
"DIFF tags": [[i] for i, s in enumerate(sentences)],
"RICH tags": [[1, 2] for s in sentences],
"RICHER tags": [[1, 2, 3, 4] for s in sentences],
"RICHEST tags": [[1, 2, 3, 4, 5, 6, 7, 8, 9] for s in sentences],
}
- 아마도, 당연히,
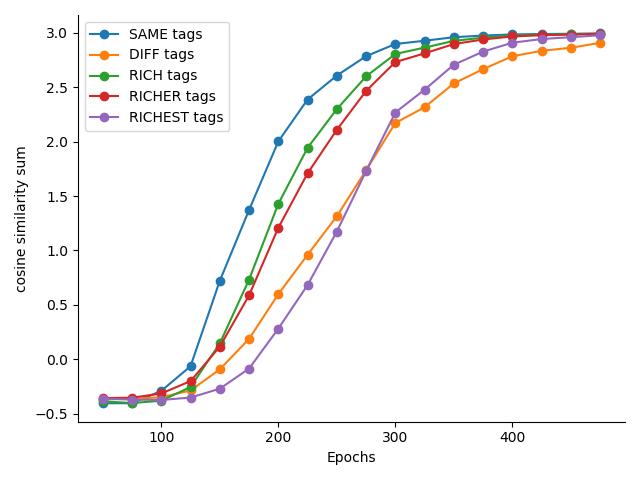
SAME tags의 경우, 문서들의 유사도가 높게 나올 것이며,DIFF tags는 문서들의 유사도가 낮게 나와야 합니다. 그리고 나머지들은, 아마도 그 사이에 존재하게 되겠죠. - 그리고, 일단은 그냥 document들의 모든 조합의 similarity를 합친 값을 지표로 처리하기로 했습니다. 정확하지는 않아도, 이정도면 대략적인 패턴은 보일테니까요.
- 실행해서 epoch에 따른 similarity의 변화를 보면 다음과 같습니다. 예상했던 것처럼, tage를 동일하게 했을 때, 유사도가 가장 빠르고, 모두 다르게 했을 때, 제일 낮고, 같지만 중복의 tag를 여러 개 넣었을 때 그 사이사이에 있게 되죠.
wrap-up
- 사실, 이건 해보지 않아도, 대충 예상가능한 것이기는 했습니다만, 늘 말하지만, 저는 그것이 똥인지 된징인지 찍어먹어보는 종류의 사람이기 때문에, 이번에도 찍어서 먹어봤습니다.
tags를 미리 적용해서 학습을 시키는 것이 경우에 따라서 학습을 빠르게 해줄 수 있다는 강점이 있을 수 있지만, 늘 그렇듯 왜곡의 문제점을 가지고 있습니다. 가능하면,tags를 설정해서 진행한 경우와,tags를 unique하게 설정해서 진행한 경우를 구분하여 두는 것이 좋을 것 같아요.
reference
raw-code
import gensim
from gensim.models.doc2vec import TaggedDocument
from sklearn.metrics.pairwise import cosine_similarity
import itertools
import matplotlib.pyplot as plt
# 학습할 sentence
sentences = [
"He is a boy", "He is a man", "She is a girl"
]
sentences = [s.lower().strip().split(" ") for s in sentences]
# 각 Document별로 다양한 방식으로 TAG를 설정해줌
tags_dict = {
"SAME tags": [[1] for s in sentences],
"DIFF tags": [[i] for i, s in enumerate(sentences)],
"RICH tags": [[1, 2] for s in sentences],
"RICHER tags": [[1, 2, 3, 4] for s in sentences],
"RICHEST tags": [[1, 2, 3, 4, 5, 6, 7, 8, 9] for s in sentences],
}
# tags_sim_along_epoch_dict
# tag 스타일별로 epoch이 커지면서 문서들간의 similarity 합을 리스트로 저장함.
tags_sim_along_epoch_dict = {k: [] for k, v in tags_dict.items()}
# epoch_lst: epoch을 변경하며 학습
epoch_lst = [i for i in range(50, 500, 25)]
for k, tags in tags_dict.items():
print(f"== {k}")
# tag update
tagged_docs = []
for s, tags in zip(sentences, tags):
tagged_docs.append(TaggedDocument(words=s, tags=tags))
# epoch을 변화시키며
for epchs in epoch_lst:
# BUILD vocab and TRAIN tagged_documents
DVmodel = gensim.models.doc2vec.Doc2Vec(vector_size=50, min_count=1)
DVmodel.build_vocab(tagged_docs)
DVmodel.train(tagged_docs, total_examples=len(tagged_docs), epochs=epchs)
# 현재의 상태에 대해서
cos_sum = 0
for s1, s2 in itertools.combinations(sentences, 2):
v1 = DVmodel.infer_vector(s1).reshape(1, -1)
v2 = DVmodel.infer_vector(s2).reshape(1, -1)
cos_sum += cosine_similarity(v1, v2)[0][0]
tags_sim_along_epoch_dict[k].append(cos_sum)
#print(f"{cos_sum: .2f}", end=" ")
# draw figure
plt.figure()
for k, v in tags_sim_along_epoch_dict.items():
plt.plot(epoch_lst, v, marker='o', label=k)
ax = plt.gca()
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
plt.legend()
plt.xlabel("Epochs"), plt.ylabel("cosine similarity sum")
plt.tight_layout()
plt.savefig("diff_tags.png")
댓글남기기