triangular dist.를 정리합니다.
어떤 분포로 시뮬레이션을 해야 하나
- 저는 business process를 연구합니다. 요즘에는 business process에서도 simulation쪽에 관심이 있는데, 개별 단위의 activity를 어떤 분포로 모델링해야 하는지를 고민하고 있습니다.
- normal distribution으로도 할 수 있기는 한데, 이 경우는 우연히라도 음수가 나오면 문제가 생길 수 있고(물론 그럴 경우에는 다시 값을 찾는 식으로 세팅해도 되기는 합니다만
- uniforn distribution은 현실성이 없는 것 같고,
- 아무튼 그래서 찾다보니 보통 이럴 때는 triangular distribution을 많이 쓴다고 해서 그 분포를 간단하게 정리해봤습니다.
triangular distributino
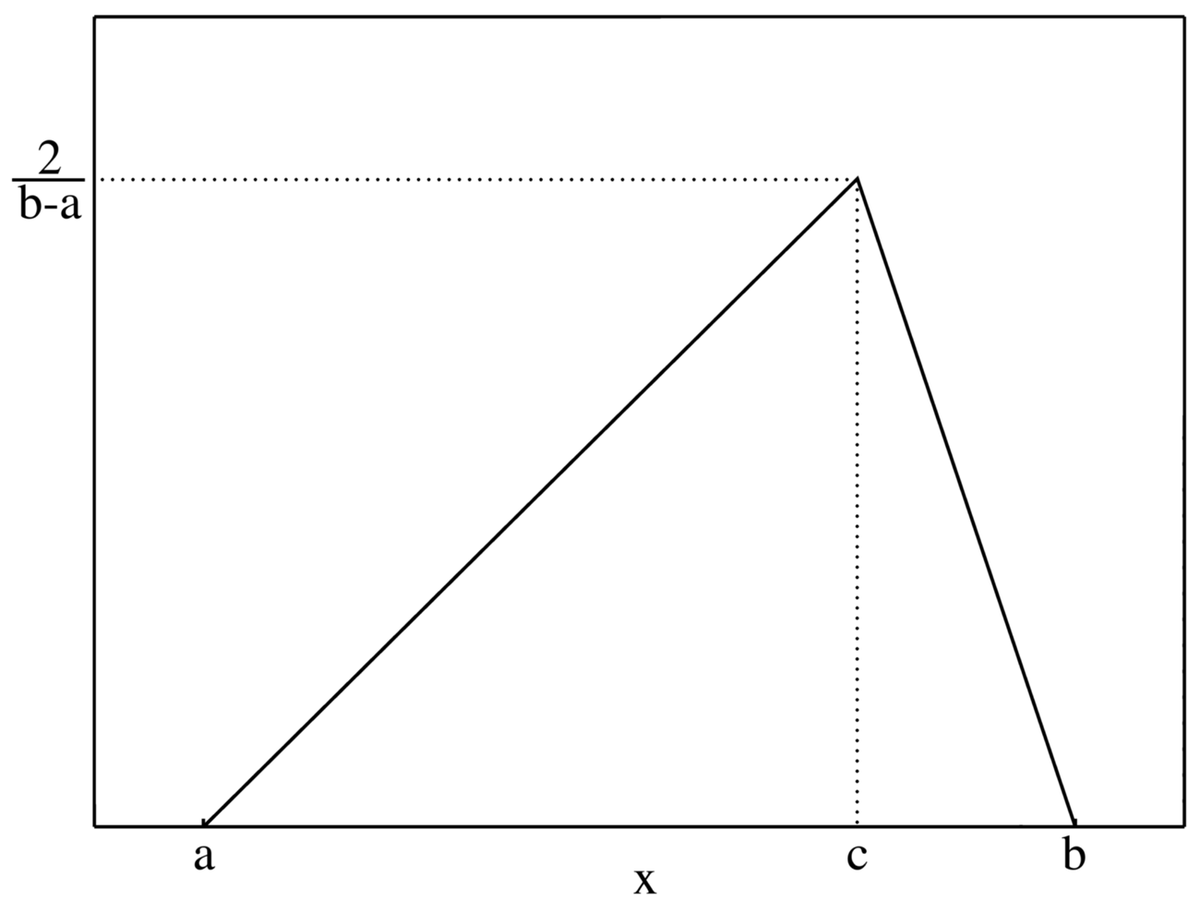
- 아래 그림처럼 Probability density function을 가진다고 보면 됩니다.
- min, max, mode로 pdf를 설정하고 그 값에 따라서 랜덤하게 값이 출력된다고 보면 되겠네요.
use
- 영문 위키피디아를 보면 이 분포가 business simulation에서 많이 사용된다고 합니다.
-
일반적으로 비즈니스 데이터는 그 양이 적기 때문에 특정 분포로 모델링하는 것이 약간 어렵습니다. 따라서 triangular 분포를 많이 쓴다고 하네요. 따라서 이를 “lack of knowledge” distribution이라고 한다고도 합니다.
- 아무튼,
numpy에 있기 때문에 간단하게 사용해보겠습니다.
import numpy as np
np.random.triangular(left =1, right=10, mode=8, size=10)
array([ 5.5620038 , 4.34801655, 4.34366856, 4.24489226, 5.38723788,
6.20987037, 6.07688502, 5.8468733 , 4.60461512, 4.57123227])
댓글남기기