structural equivalence를 활용해 두 노드 간의 등위성을 분석해봅시다.
네트워크 상에서 비슷한 역할을 하는 노드를 찾아봅시다!
- structural equivalence, ‘구조적 등위성’으로 표현할 수 있을텐데, 네트워크 상에서의 연결성을 확인해보면, 두 노드가 ‘의미적으로 비슷하다’는 것을 의미하는 성질입니다.
- 대략 다음 네트워크를 보시면, 구조적으로
n1과n2의 네트워크 상에서의 역할이 비슷하다는 것을 대략 알 수 있습니다.- 현재의 network는 non-weigh, non-directional 입니다. 방향성이 있는 경우, 그리고 weight가 있는 경우에는 계산방법이 달라집니다.
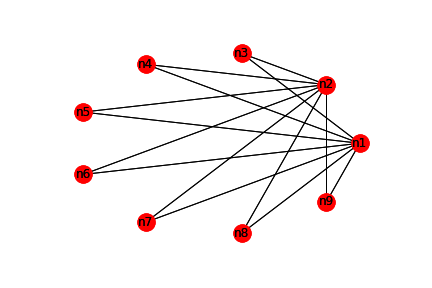
g = nx.Graph()
g.add_nodes_from(
[("n{}".format(n), {'weight':1.0}) for n in range(1, 10) ]
)
g.add_edges_from(
[('n1', n, {'weight':1.0}) for n in g.nodes()] + [('n2', n, {'weight':1.0}) for n in g.nodes()]
)
g.remove_edge('n1', 'n2')
for n1 in g.nodes():
try:
g.remove_edge(n1, n1)
except:
continue
nx.draw_networkx(g, nx.shell_layout(g))
plt.axis('off')
plt.savefig('../../assets/images/markdown_img/structural_equi-201805111758.png')
- 이를
node to node matrix의 형태로 변환하면 각 row는 node에서 node에 대한 vector가 되고, 이를 표준화한 다음 개별 node 간의 거리를 계산하면, 서로 가깝게 위치한 node 들을 찾을 수 있습니다.- 개별 값을 numerical하게 고려해도 되고, boolean value로 생각해도 상관없습니다.
- 물론 여기서 중요한 것은 어떻게 노드 간의 거리를 측정할 것인가? 가 되겠죠. 유클리디안 이 적합하냐 자카드가 적합하냐, 코사인이 적합하냐 hamming이 적합하냐 등등등, 가장 좋은 방법은 그냥 일단 다 해보는 것인데, 표준화를 먼저 한 다음에 하는 게 좋을 것 같습니다.
- 이제 슬슬 numpy, sklearn, scipy에 있는 scaling 기법들을 사용해주면 좋을 것 같습니다.
- 공부하다가 다시 보니, 이 부분은 아래 처럼 복잡하게 할 필요 없이,
nx.adjacency_matrix로 처리가 되네요. 자동으로weight부분을 처리해줍니다.
import pandas as pd
node_to_node_mat = {}
for n1 in g.nodes():
node_to_node_mat[n1] = {}
for n2 in g.nodes():
try:
node_to_node_mat[n1][n2] = g[n1][n2]['weight']
except:
node_to_node_mat[n1][n2] = 0
node_to_node_mat = pd.DataFrame(node_to_node_mat)
print(node_to_node_mat)
n1 n2 n3 n4 n5 n6 n7 n8 n9
n1 0.0 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
n2 0.0 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
n3 1.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
n4 1.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
n5 1.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
n6 1.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
n7 1.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
n8 1.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
n9 1.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
using it on keyword network.
- keyword to keyword matrix 로부터 개별 row(or vector)를 keyword의 특성을 의미하는 numerical representation으로 가정하고, 이 둘 간의 거리가 가까우면 해당 keyword는 유사하다, 라고 해석할 수도 있다.
- 또한 이런 식으로 거리로 고려하면, 이 거리를 활용해서 clustering 또한 가능함.
- 다만, 아직 정리를 다 하지는 않았지만, 모든 keyword pair에 대해서 distance를 계산해서(euclidean, mahalanobis, jaccrad) 상위의 키워드 pair를 확인해도, 딱히 유의미한 도출이 되지 못함.
- 이는 내가 column을 너무 많이 잡았거나 혹은 작게 잡았거나, 그리고 반드시 index의 수와 column수가 같을 필요는 없음.
- 다시 말해, bipartite하게 네트워크를 구성해서 거기로부터 어떤 값을 가져오는 것이 더 적합하게 느껴지기도 함.
by bipartite network
- 또한 이후에는 node to node 가 아닌, bipartite한 구조를 만들어서 측정할 수도 있을 것 같습니다. 요거는 또 다른 포스트로 한번 정리를 해두어야 겠네요.
댓글남기기