python lib) python with iterators - itertools, functools
remind
- 대략 1년전에 만들었던 자료를 다시 올립니다. 과거에는
itertools가 좋은 라이브러리라고 생각했었는데, 이제는 그냥 필요할때, generator로 직접 정의해서 쓰는 게 더 편해서, 거의 쓰지 않습니다. - 다만,
chain.from_iterable이나,combinations의 경우는 빨라서 쓰는 경우가 좀 있습니다.
원래 계획: ==”iterator를 쓰면 이렇게 빨라진다 몰랐지 이 펑알못들아”
현실:
그냥 하자…몰라 시바….
- 데이터 스트림을 나타내는 객체이며, 한 번에 하나의 데이터를 반환한다.
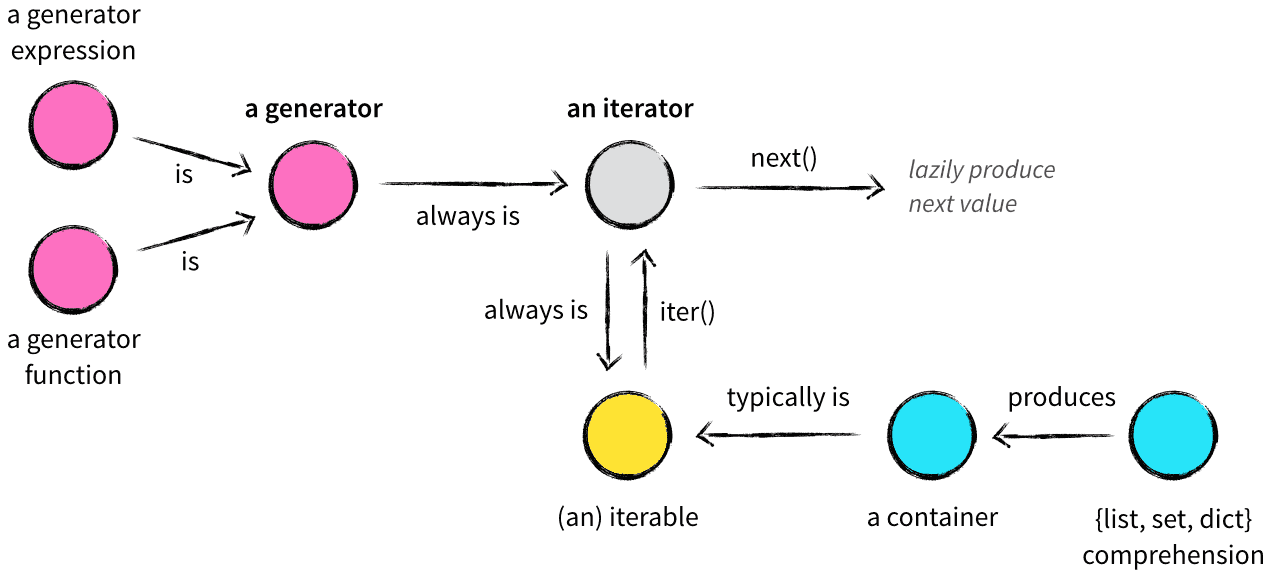
- python iterator는
next()를 호출하여 해당 데이터 스트림의 다음 요소를 가져올 수 있음 - next()했을 때 없을 경우, StopIteration exception을 일으킨다.
iter()는 iterator를 지원하는 객체(iterable object: list, dict)를 iterator로 변환해준다.- iterator는 for, max, min, in 등의 함수 및 오퍼레이터에서 사용될 수 있다.
- python에서 function-style programming하기 위해서는
lazy evaluation을 지원하는 것이 필수적이며, 이를 위해서, iterator를 사용하는 것이 필수적임lazy evaluation(연산식의 계산을 바로 하지 않고 최후까지 늦추는 방식, 게으른 연산)- 함수형 프로그래밍에서 g(f input)으로 설계되어 있을 때, 만약 f의 연산에 의해서 나온 값이 return되어 컴퓨터의 임시 메모리에 저장되었다가 g의 연산으로 간다면, 해당 연산의 효율성은 크게 떨어지게 된다.
- 특히, f의 아웃풋이 무지막지하게 클 경우, 해당 메모리에서 이를 제어할 수 없을 수도 있음.
- 따라서, g와 f를 결합하여 하나의 펑션처럼 만들고 그 다음에 input 값을 불러와서 처리하면, 연상의 효율성이 증가함
- 텐서플로우 또한 이와 유사한 형태로 설계되어 있음.
- 함수형 프로그래밍 언어에서는 modularity를 지원해야 하며 따라서
lazy evaluation이 지원되어야만 함. - 비함수형 프로그래밍의 경우에는 이것이 불가하기 때문에, 연산의 효율성을 높이기 위해서는 함수를 나누어 정의할 수 없고, 하나로 통합하여 정의해야 한다. 다만 이는 modularity를 저해하기 때문에, 문제가 발생함.
- 함수형 프로그래밍에서 g(f input)으로 설계되어 있을 때, 만약 f의 연산에 의해서 나온 값이 return되어 컴퓨터의 임시 메모리에 저장되었다가 g의 연산으로 간다면, 해당 연산의 효율성은 크게 떨어지게 된다.
yield등을 이용해서 iterator를 만들어주는 generator를 만들 수도 있음. 이는 뒤에서 더 설명함-
쓸데없이 for문이 nested nested…으로 들어가면 코드가 안 예쁜데(개인적인 취향일 수 있음), itertools를 쓰면 코딩을 좀 예쁘게 할 수 있음.
- list를 안 쓰고, 모두 iterator로 만들어서 처리하면, (lazy evaluation을 지원할 경우) 계산에서 확실한 이점이 있어야 하는데, 내 실험상으로는 그렇지 않음.
- 오히려 그냥 list를 쓰는게 더 빠름….망함….몰라 시바…
iterator basic
- 코딩할 때
iter(list),list를 프린트 했을 때 값이 다른 것을 알 수 있음. - 특히, iterator의 경우 아직 값이 모두 불러진 것은 아니기 때문에, 내부의 값을 integer position으로 indexing할 수는 없음 => 에러가 발생함
iter_lst = ["a", "b"] print(iter_lst) print(iter(iter_lst)) print(iter(iter_lst)[0]) # iteragor를 integer position으로 접근하면 error occur
['a', 'b']
<list_iterator object at 0x00000158531F0C18>
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-1-f2ee7ca04cc9> in <module>()
2 print(iter_lst)
3 print(iter(iter_lst))
----> 4 print(iter(iter_lst)[0]) # iteragor를 integer position으로 접근하면 error occur
TypeError: 'list_iterator' object is not subscriptable
- 앞서 말한 것처럼,
iterator의 각 요소는next로 접근할 수 있으며, 값이 더 이상 없을 경우에는, ‘raise StopIteration’
a = iter([1,2,3])
while True:
print(next(a))
1
2
3
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-2-46a6f86ddaac> in <module>()
1 a = iter([1,2,3])
2 while True:
----> 3 print(next(a))
StopIteration:
- 아니면 iterator를 list로 바꾸어서 subcriptable하게 만든 다음, integer position으로 접근해도 됨
- subscriptable: It basically means that the object implements the getitem() method. In other words, it describes objects that are “containers”, meaning they contain other objects. This includes lists, tuples, and dictionaries.
a = iter([1,2,3])
print(list(a)[1])
2
iterator를 지원하는 자료형(iter()가 가능한 자료형)
listdictionary- file: file의 iterator는
readline()의 결과를 리턴, 여기서는 file만 설명하겠음
# write file
f = open("test.txt", "w")
for i in range(0, 3):
f.write(str(i)+"번째 줄입니다\n")
f.close()
- iterator로 처리하지 않을 경우에는 아래처럼 전체 file 값을 다 긁어와야 함.
- 파일의 크기가 작다면 문제없겠지만, 클 경우에는 문제가 발생함
f = open("test.txt", "r")
temp = f.readlines()
print(type(temp), temp)
<class 'list'> ['0번째 줄입니다\n', '1번째 줄입니다\n', '2번째 줄입니다\n']
- f 자체가
iterator이며next를 이용해서 라인 바이 라인으로 부를 수 있음.
# read file as iterator
f = open("test.txt", "r")
while True :
try:
print(next(f))
except:
break
f.close()
0번째 줄입니다
1번째 줄입니다
2번째 줄입니다
Generator
generator는iterator를 만들기 쉽게 하는 함수- 일반적인 함수는 값을 계산해서 반환하지만,
generator는iterator를 반환한다. yield키워드를 포함하는 함수가 generator.yield n는 return n and stop정도로 이해하면 됨
def generate_ints_less_than(n):
for i in reversed(range(0, n)):
yield i
#reversed 는 iterator object를 return
a = generate_ints_less_than(1000)
for i in range(0, 5):
print(next(a))
999
998
997
996
995
Generator expressions and list comprehensions
- list comprehension과 유사하지만, 대괄호[]가 아닌 소괄호()로 묶을 경우, generator가 생성됨
- generator expression은 iterator를 반환하고, listcomps는 list를 반환한다.
- listcomp와 다르게 genexp는 materialize하지 않기 때문에, 무한 iterator, 대용량의 데이터를 사용하는데 적합하다
line_lst = [" a ", " b ", " c "]
stripped_iter = (line.strip() for line in line_lst) # Generator expression
stripped_list = [line.strip() for line in line_lst] # List comprehension
print( stripped_iter, type(stripped_iter) )
print( stripped_list, type(stripped_list) )
while True:
try:
print(next(stripped_iter))
except:
break
<generator object <genexpr> at 0x000001585326DDB0> <class 'generator'>
['a', 'b', 'c'] <class 'list'>
a
b
c
- 이건 그냥 심심해서 해보는 비교임
- 존나 긴 등차수열에서 맨 앞 다섯 개의 수만 불러내는 (쓸데없는) 짓을 할때, 시간측면에서 무엇이 가장 합리적인가
rangelistiter(list)iter(range)generator
# range를 쓸 경우
import time
t_range = time.time()
a = range(10, -99999999, -1)
for i in range(0, 5):
print(a[i])
t_range = time.time() - t_range
print(t_range)
10
9
8
7
6
0.0005004405975341797
# list를 쓸 경우
t_lst = time.time()
a = [i for i in range(10, -99999999, -1)]
for i in range(0, 5):
print(a[i])
t_lst = time.time() - t_lst
print(t_lst)
10
9
8
7
6
8.14093542098999
# iter + list를 쓸 경우,
t_iter_lst = time.time()
a = iter([i for i in range(10, -99999999, -1)])
for i in range(0, 5):
print(next(a))
t_iter_lst = time.time() - t_iter_lst
print(t_iter_lst)
10
9
8
7
6
11.865921974182129
# iter + range를 쓸 경우,
t_iter_range = time.time()
a = iter(range(10, -99999999, -1))
for i in range(0, 5):
print(next(a))
t_iter_range = time.time() - t_iter_range
print(t_iter_range)
10
9
8
7
6
1.8047053813934326
# generator를 쓸경우
t_gen = time.time()
def generate_ints_less_than(n):
i = n
while True:
yield i
i = i-1
a = generate_ints_less_than(10)
for i in range(0, 5):
print(next(a))
t_gen = time.time() - t_gen
print(t_gen)
10
9
8
7
6
0.0004999637603759766
- generator가 짱 먹음.
- generator ««««< iter(range) = range < list < iter(list)
- 사실 당연하긴 함. list는 전체를 복사해서 쓰는데 generator는 앞 쪽만 쓰니까 이런 문제가 없음.
- generator를 쓰지 않을 거면, range를 쓰는게 좋음.
iterator와 함께 사용할 수 있는 built-in function
python2에서는 built-in function들이 list를 return했지만, python3에서는 iterator를 return
- 간단하게는 아래와 같은 list에서 사용하는 function들이 모두 가능함
iter_lst = (i for i in range(0, 10))# iterator를 return하는 generator
print("min:", min(iter_lst))
iter_lst = (i for i in range(0, 10))
# 앞에서 이미 min함수가 iterator를 한번 훑고 지나갔기 때문에, 다시 iterator를 만들어줘야함.
print("max:", max(iter_lst))
iter_lst = (i for i in range(0, 10))
print(100 in iter_lst)
iter_lst = (i for i in range(0, 10))
print(3 in iter_lst)
min: 0
max: 9
False
True
- 조금 복잡하게 해봅시다.
map: iterable한 자료구조(list, dictionary)의 각 원소가 function에 입력되었을 때의 return값을 원소로 가지는 iterator를 return- 여기서는 unary operator
def lower(s):
return s.lower()
def upper(s):
return s.upper()
lst = ["a", "b", "c"]
# 괜히 복잡하게 설계했지만, 그냥 a를 대문자 => 소문자 => 다시 대문자로 바꾸는 쓸데없는 짓임
a = map(upper, map(lower, map(upper, lst)))
print(type(a), a)
while True:
try:
print(next(a))
except:
break
<class 'map'> <map object at 0x0000015853298828>
A
B
C
여기서는 binary operator
def oper(a, b):
return (a+a)*(b+b)
lst1 = [1,2,3]
lst2 = [2,4,6]
a = map(oper, lst1, lst2)
print(type(a), a)
while True:
try:
print(next(a))
except:
break
<class 'map'> <map object at 0x0000015853298CC0>
8
32
72
- 분명히 lazy evaluation이 더 좋다고 했으니까, iterator를 return 하는 map을 써서 하면 존나 빠르겠지??
- 리스트의 원소마다 lower 함수를 7번 먹이는 (쓸데없는) 짓을 하는데, 하나는 map을 써서 하고, 다른 하나는 일일이 하나씩 바꿔준다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
def lower(s):
return s.lower()
def upper(s):
return s.upper()
lst_t_df = []
iter_t_df = []
for i in range(5, 25):
size = 2**i
lst_t = time.time()
c_lst = [ chr(np.random.randint(ord('a'), ord("z"))) for i in range(0, size) ]
for i in range(0, len(c_lst)):
c_lst[i]=c_lst[i].lower()
for i in range(0, len(c_lst)):
c_lst[i]=c_lst[i].lower()
for i in range(0, len(c_lst)):
c_lst[i]=c_lst[i].lower()
for i in range(0, len(c_lst)):
c_lst[i]=c_lst[i].lower()
for i in range(0, len(c_lst)):
c_lst[i]=c_lst[i].lower()
for i in range(0, len(c_lst)):
c_lst[i]=c_lst[i].lower()
for i in range(0, len(c_lst)):
c_lst[i]=c_lst[i].lower()
lst_t = time.time() - lst_t
# iterator로 처리함
iter_t = time.time()
c_iter = ( chr(np.random.randint(ord('a'), ord("z"))) for i in range(0, size) )
c_iter = list(map(lower, map(lower, map(lower, map(lower, map(lower, map(lower, map(lower, c_iter))))))))
iter_t = time.time() - iter_t
lst_t_df.append(lst_t)
iter_t_df.append(iter_t)
lst_iter_compp_df = pd.DataFrame({"lst_t":lst_t_df, "iter_t":iter_t_df})
print( lst_iter_compp_df)
lst_iter_compp_df.plot()
plt.savefig("lst_iter_comparison.svg")
plt.savefig("lst_iter_comparison.png")
iter_t lst_t
0 0.015510 0.014509
1 0.000000 0.001001
2 0.001001 0.001000
3 0.006004 0.005003
4 0.004503 0.004002
5 0.006004 0.006004
6 0.012008 0.014009
7 0.032021 0.024515
8 0.047532 0.046531
9 0.096564 0.091562
10 0.188626 0.182122
11 0.374752 0.362242
12 0.758005 0.733989
13 1.515512 1.483490
14 3.030023 2.933459
15 6.768023 6.745004
16 12.456354 12.001580
17 25.116780 25.245859
18 50.883569 49.693537
19 99.768218 97.382560
- list와 iterator의 속도에 큰 차이가 없는 것을 알 수 있음.

- 두 가지 정도의 간단한 가설을 세울 수 있음.
1) list가 활용될 때, 이미 lazy evaluation이 지원됨.
2) python에서 지원하는 lazy evalution에 문제가 있음.
3) 내가 사용한 data의 사이즈(2** 25) 가 충분히 scalable하지 않음- 그런데, 2 ** 25면 1000조 사이즈임 4) functional programming을 제대로 쓰려면, 분산형 컴퓨팅 부분을 처리해줘야 하는데, 여기서는 그 부분이 고려되지 못함
- 좀 더 자세하게 본다면, 좋겠지만, 귀찮고, 앞으로 큰 문제가 없는 한 그냥 list를 쓰겠음.
- 다만, 속도와 무관하게, 사용하는 memory에서는 문제가 발생하지 않음.
# list의 경우는
# k = 1000000000 이 때 memory 가 부족해짐. 십억
k=100
test = list("abc")*k
print(test[k*3-1])
import time
# 하지만 iterator를 쓰면, 존나 큰 값에서도 에러없이 돌아가긴 함.
# k = 10000000000 백억.
# 단 시간은 753초가 걸림.
# 753.5034182071686
k = 100
a = time.time()
test = chain.from_iterable(repeat("abc", k))
print( list(islice(test, k*3-1, k*3)) )
b = time.time()
c = b-a
#print(list(test))
솔직히 딱 이 시점부터, 과연 iterator에게 미래는 있는가? 라는 생각이 들기는 함…. 아무튼 그래도 iterator가 무엇인지는 알아야 하니까 좀 더 공부해봅시다..
filter: iterable한 자료구조(list, dictionary)의 각 원소가 function에 입력되었을 때 True인 원소들만 원소로 가지는 iterator를 return
####filter
def is_even(x):
return (x%2)==0
a = filter(is_even, range(10))
# 즉 여기서는, 짝수인 경우만 남기고, 걸러냄
print( a )
print(next(a))
print(next(a))
print(next(a))
<filter object at 0x000001580722F0F0>
0
2
4
enumerate: iterable한 자료구조에 대해서 순서를 포함한 원소를 가지는 iterator를 return
###enumerate
a = enumerate( range(10, 15) )
print(next(a))
print(next(a))
print(next(a))
(0, 10)
(1, 11)
(2, 12)
- 사실 굳이 iterator를 쓰지 않고, list로 처리하는게 더 편할 때도 있음.
- 그럴때는 그냥 list를 붙여준다.
a= map(lambda x: x+1, range(1, 10))
print(a)
print(list(a))
<map object at 0x00000158071F8A20>
[2, 3, 4, 5, 6, 7, 8, 9, 10]
itertools
- 하지만 매번, 내가 필요한 iterator들을 직접 짜야하는것은 고통.
- 그러지말라고 우리가 파이썬을 하는거 아닙니까아아아 여러부우우운!!!
- 그래서
itertools를 씁시다
import itertools as ittls
itertools.count()
- infinite count
- 보통 대부분의 list는 finite하지만, iterator의 경우, 아직 발생하지 않은 수열이므로, 끝없이 출력할 수 있다.
print("using itertools")
count_iter = ittls.count(10, step=3)
print(count_iter)
for i in range(0, 5): # 만약 여기서 range를 정하지 않는다면, 무한히 출력하게 됨.
print( next(count_iter) )
using itertools
count(10, 3)
10
13
16
19
22
- 사실 itertools를 굳이 쓸 필요 없기는 함…쭈글쭈글….안 써도 큰 차이 없음…
print("not using itertools")
s = 10
step = 3
end = s+5*step
for i in range(s, end, step):
print(i)
not using itertools
10
13
16
19
22
itertools.cycle()
- cycle은 시퀀스를 반복하는 무한수열
a = ["a", "b", "c"]
print("using itertools")
b = ittls.cycle(a)
print(b)
for i in range(0, 5):
print(next(b))
using itertools
<itertools.cycle object at 0x000001580722C988>
a
b
c
a
b
- 사실 그냥 내가 원하는 만큼 곱해서 처리하는게 나을 수도 있음…쭈글쭈글…
print("not using itertools")
a=a*3
for i in range(0, 5):
print(a[i])
not using itertools
a
b
c
a
b
itertools.accumulate()
- python2에서의 reduce와 유사함
- 각 element에 연속적으로 function을 적용해줌
- default function은 +
a = range(1, 6)
print("using itertools")
print( list(a) )
print( list(ittls.accumulate(a)) )
print( list(ittls.accumulate(a, lambda x, y: x*y)) )
b = ["a","b","c"]
print( list(ittls.accumulate(b)) )
using itertools
[1, 2, 3, 4, 5]
[1, 3, 6, 10, 15]
[1, 2, 6, 24, 120]
['a', 'ab', 'abc']
- 다른 경우들과 유사하게, itertools를 쓰지 않더라도 비슷하게 처리할 수 있기는 함.
print("not using itertools")
print(list(a))
print( [sum(a[:i+1]) for i in range(0, len(a))] )
def temp_def(lst):
return lst[0] if len(lst)==1 else lst[0]*temp_def(lst[1:])
print( [ temp_def(a[:i+1]) for i in range(0, len(a))] )
print( [ "".join(b[:i+1]) for i in range(0, len(b))] )
not using itertools
[1, 2, 3, 4, 5]
[1, 3, 6, 10, 15]
[1, 2, 6, 24, 120]
['a', 'ab', 'abc']
itertools.chain.from_iterable
- Make an iterator that returns elements from the first iterable until it is exhausted, then proceeds to the next iterable, until all of the iterables are exhausted
- elemenet를 존나 다 긁어서 합치는 함수
x = [list(range(i*3, i*3+3)) for i in range(0, 5)]
print(x)
print("using itertools")
print(list(ittls.chain.from_iterable(x)))
[[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11], [12, 13, 14]]
using itertools
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
- 사실 itertools을 쓰지 않아도 대략 비슷한 걸 할 수 있음.
x = [list(range(i*3, i*3+3)) for i in range(0, 5)]
print("not using itertools")
k = []
for a in x:
k+=a
print(k)
print(k==list(ittls.chain.from_iterable(x)))
not using itertools
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
True
- 원래는 이러한 함수를 python2에서는 reduce가 지원했으나, 지금은 사라짐
- python만든 사람이 좆같다고 없애버림
- python3에서는 functools에서만 사용할 수 있음.
print("using functools")
import functools
print(x)
print( functools.reduce(lambda a, b: a+b, x) )
print( functools.reduce(lambda a, b: a+b, x)==k ==list(ittls.chain.from_iterable(x)))
using functools
[[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11], [12, 13, 14]]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
True
itertools.combination()
- 사실 지금부터 나오는게 그나마 유용한 부분들임
- combination은 순서를 고려하지 않고 서로 다른 set를 뽑아줌.
- 우리가 고등학교 때 배운, ‘조합’
a = ["a", "a", "b", "c"]
print("using itertools")
for i in range(1, len(a)+1):
print( list(ittls.combinations(a, i)) )
using itertools
[('a',), ('a',), ('b',), ('c',)]
[('a', 'a'), ('a', 'b'), ('a', 'c'), ('a', 'b'), ('a', 'c'), ('b', 'c')]
[('a', 'a', 'b'), ('a', 'a', 'c'), ('a', 'b', 'c'), ('a', 'b', 'c')]
[('a', 'a', 'b', 'c')]
itertools.combinations_with_replacement()
- combination이랑 같지만, 중복을 허용.
a = ["a", "b", "c"]
print("using itertools")
for i in range(1, len(a)+1):
print( list(ittls.combinations_with_replacement(a, i)) )
using itertools
[('a',), ('b',), ('c',)]
[('a', 'a'), ('a', 'b'), ('a', 'c'), ('b', 'b'), ('b', 'c'), ('c', 'c')]
[('a', 'a', 'a'), ('a', 'a', 'b'), ('a', 'a', 'c'), ('a', 'b', 'b'), ('a', 'b', 'c'), ('a', 'c', 'c'), ('b', 'b', 'b'), ('b', 'b', 'c'), ('b', 'c', 'c'), ('c', 'c', 'c')]
itertools.product()
- 서로 다른 set에서 가능한 경우를 모두 뽑아줌
a = ["a", "b", "c", "d"]
b = ["A", "B", "C", "D"]
c = [1,2,3,4]
print("using itertools")
k = list(ittls.product(a,b,c))
print(len(k))
print(k)
using itertools
64
[('a', 'A', 1), ('a', 'A', 2), ('a', 'A', 3), ('a', 'A', 4), ('a', 'B', 1), ('a', 'B', 2), ('a', 'B', 3), ('a', 'B', 4), ('a', 'C', 1), ('a', 'C', 2), ('a', 'C', 3), ('a', 'C', 4), ('a', 'D', 1), ('a', 'D', 2), ('a', 'D', 3), ('a', 'D', 4), ('b', 'A', 1), ('b', 'A', 2), ('b', 'A', 3), ('b', 'A', 4), ('b', 'B', 1), ('b', 'B', 2), ('b', 'B', 3), ('b', 'B', 4), ('b', 'C', 1), ('b', 'C', 2), ('b', 'C', 3), ('b', 'C', 4), ('b', 'D', 1), ('b', 'D', 2), ('b', 'D', 3), ('b', 'D', 4), ('c', 'A', 1), ('c', 'A', 2), ('c', 'A', 3), ('c', 'A', 4), ('c', 'B', 1), ('c', 'B', 2), ('c', 'B', 3), ('c', 'B', 4), ('c', 'C', 1), ('c', 'C', 2), ('c', 'C', 3), ('c', 'C', 4), ('c', 'D', 1), ('c', 'D', 2), ('c', 'D', 3), ('c', 'D', 4), ('d', 'A', 1), ('d', 'A', 2), ('d', 'A', 3), ('d', 'A', 4), ('d', 'B', 1), ('d', 'B', 2), ('d', 'B', 3), ('d', 'B', 4), ('d', 'C', 1), ('d', 'C', 2), ('d', 'C', 3), ('d', 'C', 4), ('d', 'D', 1), ('d', 'D', 2), ('d', 'D', 3), ('d', 'D', 4)]
itertools.permutations()
- 조합* 순서 고려, 이런게 순열이었나…
a = ["a", "b", "c"]
print("using itertools")
for i in range(1, len(a)+1):
print("comb:", list(ittls.combinations(a, i)))
print("perm:", list(ittls.permutations(a, i)))
using itertools
comb: [('a',), ('b',), ('c',)]
perm: [('a',), ('b',), ('c',)]
comb: [('a', 'b'), ('a', 'c'), ('b', 'c')]
perm: [('a', 'b'), ('a', 'c'), ('b', 'a'), ('b', 'c'), ('c', 'a'), ('c', 'b')]
comb: [('a', 'b', 'c')]
perm: [('a', 'b', 'c'), ('a', 'c', 'b'), ('b', 'a', 'c'), ('b', 'c', 'a'), ('c', 'a', 'b'), ('c', 'b', 'a')]
결론

그래도 뭔가…
- 알고 있다 라고 생각했던 iterator를 더 명확하게 알게 됨
- 어줍잖게 functional programming한다고 깝치지 말고, 가지고 있는 list나 똑바로 쓰자는 교훈
- 어떻게 list가 iterator보다 빠른가 는 궁금하긴 한데, 이 부분은 건드릴 수록 엄청나게 큰 일이 될것 같으므로, 멈춘다. 이후에 어떻게 되겠지…
- scala 같은 진짜 functional programming 공부를 좀 해보면 어떨까 라는 생각이 듬.
참고문헌
https://docs.python.org/3/library/itertools.html#itertools.count
댓글남기기