슬랙에 학생식당 메뉴 알려주는 봇 만들기
intro
- 과거에 매일 학생 식당 메뉴를 확인하는 것이 귀찮아서 슬랙에 봇을 만들었던 적이 있습니다. 그 내용을 정리해서 업로드합니다.
motivation
- 주로 학생식당이나 교직원식당에 밥 먹으러 가는데, 메뉴가 뭐 나오는지 매번 찾는 것이 귀찮았습니다.
- 그래서 생각해보니, 식당 메뉴는 사이트에서 제공되고, 내용을 긁어와서 처리하고 slack api를 이용하면, 비교적 쉽게 만들 수 있지 않을까? 라는 생각이 들어서 무작정 시작함(주말동안 이거함)
program spec(very simple)
- 매일 11시30분에 학생식당/교직원식당 메뉴 슬랙에 공지
- 매일 17시에 학생식당/교직원식당 메뉴 슬랙에 공지
code
required module
import pandas as pd # read_html 함수 이용
import datetime as dt # 시간 처리
import requests # http 처리 모듈
import time # 프로그램이 계속 돌아가면 문제가 있으므로, sleep을 위해 사용한 모듈
from slacker import Slacker
function defintion
- url을 parameter로 전달받아서, 해당 url의 식단 table(html로 저장되어 있음)을
pd.DataFrame로 변환하여 리턴해주는 함수를 정의함
def read_table_as_dataframe_from_url(url):
r = requests.get(url)
r.encoding = "utf-8"
start_str="<!-- 목록 시작 -->"
end_str="</td></tr></table>"
text = r.text[r.text.find(start_str)+len(start_str)+1:r.text.find(end_str)+len(end_str)]
raw_data = pd.read_html(text)
raw_data = raw_data[1]
# 여러 table이 있을 경우 DataFrame list로 값이 넘어옴
return raw_data
1) 학생식당 메뉴
read_student_meal_from_df()의 결과값을 parameter로 받아서, 전처리하여, 내가 원하는 데이터만 남긴 깔끔한pd.DataFrame을 리턴하는 함수를 정의함- index =
datetime.date - columns =
["breakfast", "breakfast_special", "lunch", "dinner"] - remove english words
- drop useless rows and columns
- index =
def read_student_meal_from_df(raw_data):
raw_data = raw_data[raw_data.index %3==0] # drop useless row
raw_data = raw_data[1:] # drop useless row
raw_data= raw_data.drop(5, axis=1) # drop useless column
raw_data = raw_data.drop(6, axis=1) # drop useless column
date_str_lst = [ x[:len(x)-4] for x in raw_data[0]]# delete weekdays
date_lst = [dt.datetime.strptime(str(dt.date.today().year)+date_str, "%Y%m-%d") for date_str in date_str_lst]
date_lst = [x.date() for x in date_lst]
raw_data.index = date_lst
raw_data = raw_data.drop(0, axis=1)
raw_data.columns = ["breakfast", "breakfast_special", "lunch", "dinner"]
for i in raw_data.index:
for j in raw_data.columns:
for k in range(0, len(raw_data[j][i])):
if ord(raw_data[j][i][k]) in range(1, ord("~")):
#non-korean delete
raw_data[j][i]=raw_data[j][i].replace(raw_data[j][i][k], " ")
while " " in raw_data[j][i]:
# delete whitespace
raw_data[j][i]=raw_data[j][i].replace(" ", " ").strip()
raw_data[j][i]=raw_data[j][i].replace(" ", ", ")
return raw_data
2) 교직원식당 메뉴
read_faculty_meal_from_df()의 결과값을 parameter로 받아서, 전처리하여, DataFrame로 리턴함- index =
datetime.date - columns =
["breakfast", "breakfast_special", "lunch", "dinner"] - remove english words
- drop useless rows and columns
- index =
- 코드를 보면 알겠지만, 사실
read_student_meal_from_df()와 유사한 부분이 많음…일단 되는지 확인하려고 대충 짜고, 된 다음에는 귀찮아서 안 고침….
def read_faculty_meal_from_df(raw_data):
raw_data = raw_data[raw_data.index%3==2]
date_str_lst = [ x[:len(x)-4] for x in raw_data[0]]
date_lst = [dt.datetime.strptime(str(dt.date.today().year)+date_str, "%Y%m-%d") for date_str in date_str_lst]
date_lst = [x.date() for x in date_lst]
raw_data.index = date_lst
raw_data = raw_data.drop(0, axis=1)
raw_data.columns = ["lunch"]
for i in raw_data.index:
for j in raw_data.columns:
for k in range(0, len(raw_data[j][i])):
if ord(raw_data[j][i][k]) in range(1, ord("~")):
#non-korean delete
raw_data[j][i]=raw_data[j][i].replace(raw_data[j][i][k], " ")
while " " in raw_data[j][i]:
# delete whitespace
raw_data[j][i]=raw_data[j][i].replace(" ", " ").strip()
raw_data[j][i]=raw_data[j][i].replace(" ", ", ")
return raw_data
main code
complete meal DataFrame
student_meal_url="http://fd.postech.ac.kr/bbs/board_menu.php?bo_table=weekly"
faculty_meal_url="http://fd.postech.ac.kr/bbs/board_menu.php?bo_table=weekly&sca=%EA%B5%90%EC%A7%81%EC%9B%90"
student_meal_df = read_student_meal_from_df( read_table_as_dataframe_from_url(student_meal_url) )
faculty_meal_df = read_faculty_meal_from_df( read_table_as_dataframe_from_url(faculty_meal_url) )
communication with slack api using Slacker
- Slacker(full-featured python interface for the Slack API)를 이용하여, python에서 slack api와 communication
- 사실 나는 간단하게 post만 할 수 있으면 되긴 함.
far far legacy way
- token은 해당 slack과 통신하기 위해서 전달받은 일종의 보안키 라고 이해하면 됨
- 사실 지금처럼 돌리는 방식은 옛날 방식임, 하지만, 나는 간단히 post만 할 수 있으면 되므로 큰 문제없음
- 아무튼 token이 code안에 있으면 문제가 있으므로 따로 txt file로 저장해서 읽어들임
- 원래는 slack 내부에 새로운 app을 만들어서, 그 app에서 나오는 token을 가지고 활용하려고 했지만, 만들어진 app이 slack과 연결되지 않음.
- 명확한 이유는 아직 모르겠고, 일단은 내가 만드려고 하는 것은 간단한 것.
- 나중에 한번 고쳐보겠음….(먼산)
token = open("../legacy_token.txt", "r").read().strip()
slack = Slacker(token)
target_channel="#general"
- 계속 시간을 돌리면서, 내가 원하는 시간에 slack 에 글을 post함
slack.chat.post_message(target_channel,output_str)- post한 다음에는 시간을 모니터링할 필요가 없으므로, 다음 시간이 올 때까지
time.sleep으로 기다림
while True:
now_datetime = dt.datetime.now() + dt.timedelta(hours=9)
if now_datetime.hour== 11 and now_datetime.minute==30 and now_datetime.second==0:
if now_datetime.date() in student_meal_df.index:
output_str = "`학생식당 점심`: " + student_meal_df["lunch"][now_datetime.date()]
slack.chat.post_message(target_channel, output_str)
if now_datetime.date() in faculty_meal_df.index:
output_str = "`교직원식당 점심`: " + faculty_meal_df["lunch"][now_datetime.date()]
slack.chat.post_message(target_channel, output_str)
time.sleep(60*60*4)
elif now_datetime.hour == 17 and now_datetime.minute==0 and now_datetime.second==0:
if now_datetime.date() in student_meal_df.index:
output_str = "`학생식당 저녁`: " + student_meal_df["dinner"][now_datetime.date()]
slack.chat.post_message(target_channel, output_str)
if now_datetime.date() in faculty_meal_df.index:
output_str = "`교직원식당 저녁`: " + faculty_meal_df["dinner"][now_datetime.date()]
slack.chat.post_message(target_channel, output_str)
time.sleep(60*60*18)
이건 고생기
docker를 활용해서 ubuntu를 돌리기(시작)
- 개인컴퓨터에서 간단하게 코드를 짜 보니까 대충 돌아감.
- 그런데, 내 컴퓨터에서 돌리는 것보다는 서버를 구축해서 돌리는 것이 적합하다고 생각됨
- 예전에 도커를 이용해서 서버를 돌려본 적이 있어서 그걸 활용하면 되지 않을까? 하고 생각함.
docker - basic

- 도커가 무엇인지 자세한 건 알려고 하면 너무 어렵고, 그냥, 일종의 가상머신 세팅을 편하게 해준다고 알기만 해도 됨
- 자세한 건 여기(docker 무작정 따라하기)를 참고
- 다만, 아래 아키텍쳐에서 보듯이, 기존의 가상머신은 hypervisor(VMWare, VirtualBox)위에 guestOS를 올려서 돌아가는데, 도커의 경우는 docker engine위에서 guestOS없이 돌아감(따라서 훨씬 가볍고, 빠름)
docker - dockerhub and immutable infrastructure
- docker도 github와 비슷하게 dockerhub라는 것이 존재함.
- 쉽게 말하면 남이 만들어놓은 개발환경이 image로 업로드되어 있으면, 이를 그대로 가져와서(pull) 같은 개발환경을 돌려볼 수 있다는 것
- 또한 docker에서 중요하게 생각하는 것은 immutable infrastructure.
- 매번 환경을 configuration하는데 많은 시간이 소요되는데, configuration보다 그냥 이미 만들어진 개발환경을 그대로 가져와서 돌리는 것이 더 효율적이라는 개념
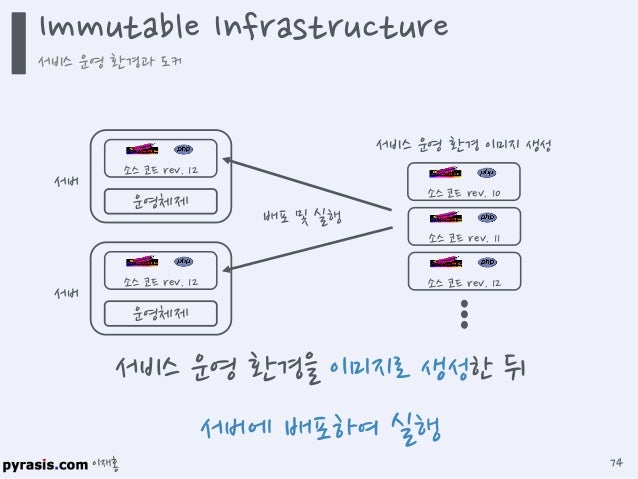
- 매번 환경을 configuration하는데 많은 시간이 소요되는데, configuration보다 그냥 이미 만들어진 개발환경을 그대로 가져와서 돌리는 것이 더 효율적이라는 개념
아무튼
- 나는 현재 컴퓨터 내에서 서버를 구축할 것이기 때문에, 최대한 가볍게 돌리는 것이 중요하고, 따라서 가벼운 우분투를 돌리는 것이 중요함
- 그래서 예전에 깔아둔 docker(docker for windows)를 실행하고, 우분투를 깔아보는데 문제가 발생함
docker pull ubuntu:latest
image operating system "linux" cannot be used on this platform
- 찾아보니까, 도커 포 윈도우즈에서 현재까지는 리눅스 컨테이너를 지원하지 않는 것 같음(윈도우 컨테이너만 지원)
- 도커 포 윈도우즈는 안되므로, 도커 포 윈도우즈는 지우고, 도커툴박스(+ virtual machine)를 깔아서 돌려본다.
- 예전에 윈도우7에서 이 형태로 우분투를 돌려봄
- 도커 포 윈도우즈와 도커 툴박스는 사용하는 가상머신이 다름(그냥 둘중 아무거나 써고 상관없음)
- 도커 포 윈도우즈 or 맥: Hyper-V, HyperKit(각 OS를 위한 경량화 가상머신)
- 도커 툴박스: VirtualBox
- 도커툴박스와 도커 포 맥의 차이
error message again
"This computer is running Hyper-V. VirtualBox won't boot a 64bits VM when Hyper-V is activated. Either use Hyper-V as a driver, or disable the Hyper-V hypervisor. (To skip this check, use --virtualbox-no-vtx-check)"
- 도커 툴박스를 돌리기 위해서는 VirtualBox가 필요한데, 이를 돌리려면, 윈도우의 기본 가상머신인 Hyper-v를 비활성화해야함.
- 제어판 ▶️ 프로그램 및 기능 ▶️ 윈도우즈 기능 켜기/끄기 ▶️ hyper-v deactivate ▶️ 컴퓨터 재시작
- 이제 docker 명령어들이 다 먹히는데, 파워쉘에서는 안 굴러가고, 도커 터미널에서만 실행됨
-
뭐 그런데 사실 되는게 어디냐….계속 진행해본다
- ubuntu 최신 버전을 긁어옴
docker pull ubuntu:latest
docker images
docker run -i -t --name hello ubuntu /bin/bash
exit()
- show all container(process)
docker ps -a
attach내가 실행한 컨테이너로 들어가기- 나올 때는 컨트롤+p, 컨트롤+q를 순차적으로 누르면 됨
docker start hello
docker ps
docker attach hello
ubuntu에서 python을 돌리기 위한 환경 세팅(시작)
- 물론, 내가 원하는 ubuntu+python+git의 개발환경을 똑같이 가진 image가 dockerhub에 있었다면, 그 image를 가지고 컨테이너를 돌리면 끝나는 문제이기는 함.
- 그런데 그렇게 완벽하게 맞는게 어디에 있겠냐..
- 아무튼 그래서 하나하나 직접 깔아본다
서버에 python 설치
apt-get update
apt-get install -y python
apt-get install -y python3-pip
python 설치 -required python module
- 사실
virtualenv를 이용해서 내부에 독립적인 환경을 세팅해주는 게 더 좋지만, 귀찮고, 내가 다른 목적으로 쓸 일도 없을 것 같아서 그냥 내부에 막 설치함
pip3 install pandas
pip3 install datetime
pip3 install requests
다른 application 설치
- terminal에서 작업하기 때문에 vim editor가 필요
- 내가 윈도우에서 코딩한 코드를 가져오기 위해서 git을 설치함.
- 물론 copy and paste로도 가능하지만, 자주 바뀔텐데, 매번 왔다갔다 하면 나도 헷갈리기 때문에 그냥 git을 쓰는게 좋음.
apt-get install vim
apt-get install git
- 우선 윈도우에서 github에 folder를 하나 만듬
- 보통 지금 폴더를 git init으로 하고 repository로 push하는 식으로 쓰려고 하는데, 이때 설정에서 삐끗하는 경우가 종종 있어서, 그냥 처음부터, git clone한 다음에 push하는 것이 훨씬 좋음.
- 현재의 서버(hello)에 내가 짜둔 코드를 가져오려면 git이 필요함
- 물론 copy and paste로 해도 되지만, 지속적으로 관리하고 업데이트하는 것을 편하게 하려면, git을 활용하는 것이 효율적.
- 우선 github에 들어가서 repository를 만들어서 그 url을 긁어온다.
- 터미널에서 내가 원하는 폴더에 git init을 하고, repository를 push하는 식으로 써도 큰 문제는 없지만, 설정에서 좀 귀찮은 일들이 있음.
- 그냥 처음부터
git clone my_repository_url하고, 코딩한 다음에 push하는 것이 훨씬 이득 - git - the simple guide
git clone my_repository_url
- 아래는 git의 관리에 둔 폴더 내부에서 코딩을 다 하고, 이(
master branch)를 기존의 repository(origin)에 올릴 때의 명령어 묶음(세 개 다 해야함)
git add *
git commit -m "first commit"
git push origin master
그러나.
- git을 이용해서 긁어온 코드에서 한글이 모두 깨짐…
- 자세히 보니, 내가 쓰는 우분투 자체에서 한글을 읽어들이지를 못함.
- 찾아보고 configuration을 다시 해봤지만, 되지 않음.
- 다시 말하면, 내가 지금까지 한 모든 과정을 다시 해야 한다는 이야기임….
자, 다시 처음부터 한글이 되는 우분투에서 세팅 해보려 함
docker를 활용해서 한글 ubuntu를 돌리기(시작)
- 한글이 되는 새로운 도커를 빌드하기로 함. docker에서 한글 지원 우분투(14.04) 이미지 만드기
- docker에서 새로운 이미지를 만든 다는 건, 기존의 이미지(일종의 개발환경)에서 branching을 해준다고 생각하면 됨.
Dockerfile에 기존의 이미지로부터 추가되어야 하는 일종의 스펙을 넣어주고 새로운 이미지를 빌드하면 도미- 내용은 잘 모름.ㅋㅋㅋㅋ아무튼 저렇게 돌리면 그 다음부터 한글이 먹힘
In Dockerfile
- 아래 내용을
Dockerfile에 작성하여 진행
FROM ubuntu:14.04
RUN apt-get update
RUN apt-get install -y language-pack-ko
# set locale ko_KR
RUN locale-gen ko_KR.UTF-8
ENV LANG ko_KR.UTF-8
ENV LANGUAGE ko_KR.UTF-8
ENV LC_ALL ko_KR.UTF-8
CMD /bin/bash
on terminal
docker build는 이미지를 빌드해주는 명령어, 마지막의./는 Dockerfile이 있는 경로
docker build --tag han_ubuntu:14.04 ./
docker run -i -t --name hello han_ubuntu:14.04 /bin/bash
- 다시 보니까, 이후에 설명하는
apt-get리스트들을 모두Dockerfile에 넣고 이미지를 만들었으면, 이후의 작업을 할 필요가 없었을듯.
ubuntu에서 python을 돌리기 위한 환경 세팅(시작)
apt-get update
apt-get install vim
apt-get git
apt-get wget
- 이후에 파이썬 모듈을 pip를 이용해서 다운받았는데, 파이썬 코드가 돌아가지 않음(아마도 디펜던시 문제로 보임)
다시 ubuntu에서 python을 돌리기 위한 환경 세팅(재시도)
- 화가 난다…
- 파이썬 관련된 것을 다 싹 지우고, (가장 안정적인)아나콘다를 다운 받기로함
wget https://repo.continuum.io/archive/Anaconda3-4.3.1-Linux-x86_64.sh
bash Anaconda3-4.3.1-Linux-x86_64.sh
- 보통 아나콘다에 pandas도 기본적으로 설치되어 있는데, 리눅스용에는 빠져있는 것 같음
- 그래서, pip를 설치해서 다시 pandas를 설치하기로 함
apt-get install python3-pip
pip3 install pandas
- 다시 에러가 발생함….
ImportError: lxml not found, please install it
- lxml module을 설치시도함 ==> 안됨….
- 사실 이 모든 문제는 pandas.read_html에서 발생하는 것임. 링크를 보면 알 수 있지만, pandas.read_html은 많은 라이브러리를 활용함
- pandas
- lxml
- html5lib
- BeautifulSoup4
- 위 라이브러리를 다 설치해주면 될 것 같지만, 계속 오류가 발생함….
- pip와 pandas를 다 지워버림==
ubuntu에서 python을 돌리기 위한 환경 세팅(재재시도)
- 기본적으로 다시 생각해보니, 파이썬을 아나콘다를 활용해서 깔았기 때문에 pip보다는 conda를 사용하는 것이 적합하다고 생각됨
conda: 아나콘다의 디펜던시 문제를 최대한 해결하면서, stable하게 만들어주는 패키치 인스톨러
- conda를 깔기 위해서는 미니콘다를 설치해줘야 함
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
- 설치했지만, 경로 문제가 있어서 경로를 다시 설정해줌. problem: “conda command not found”
export PATH="/root/miniconda3/bin:$PATH"
- 그리고 다시 pandas를 설치한다
conda install pandas
- lxml이 필요하다고 해서 또 설치한ㄷㅏㅏㅏ
conda install lxml
- 또 필요하다ㅏ..
conda install html5lib
- 또또 필요하다….
conda install BeautifulSoup4
vim
- 우분투에서 서버를 돌리기 때문에, 즉 코딩을 vim에서 해줘야함…
- 코드 파일을 껐다가 킬 때마다 탭사이즈, 셋넘을 조절해줘야 함
- set ts=4
- set nu
on terminal
- vim 프로파일인 .vimrc 파일(보통 ~폴더 아래에 있음)을 수정하자
vi ~/.vimrc
.vimrc
- 아래 내용을
.vimrc에 작성해주자
set nu
set ts=4
set shiftwidth=2
- 혹시나 싶어서…
- docker를 꺼도 백그라운드에서 돌아가나 테스트하기 위해서 도커를 끄고 돌려봄
- 됨.
and more
- 사실 굳이 우분투 위에서 돌릴 필요도 없고, 필요한 모듈 파이썬 버전만 합쳐서 이미지를 만들고, 그 이미지를 활용해서 컨테이너를 돌려도 문제는 없을 것같음.
- 다만 이 경우에는 향후 코드가 변경이 필요할때 코드를 변경하거나 하는 것이 쉽지 않음
- 지금은 내 컴퓨터에서 돌아가는데, 라즈베리파이를 하나 사서 그 위에서 돌려버리는 것도 하나의 방법
댓글남기기