node2vec은 무엇인가?
node2vec
- node는 그래프 이론에서 말하는 말 그대로 점이죠. 현실계에서는 graph와 같은 unstructured data가 많이 존재합니다. 여기서 graph중에서 특히 node를 vector로 표현하는 representational learning을 node2vec이라고 하죠.
- 관련 논문인 node2vec: Scalable Feature Learning for Networks의 초록은 대략 다음과 같습니다.
네트워크의 node와 edge에 대해서 prediction task를 수행하는 것은 feature engineering 측면에서 많은 노력이 소요된다. 최근의 연구들에서는 reprsentation learning 측면에서 feature 자체를 학습하여 이 측면에서 많은 혁신들이 있었으나, network에서 파악되는 connectivity pattern에 대해서는 제대로 학습하지 못한다는 한계를 가지고 있다. 따라서, 이를 해결하기 위해서 network의 이러한 feature를 학습할 수 있는 프레임워크인 node2vec을 제시하였다. node2vec에서는 network의 node들의 관계(neighborhood)를 우도(likelihood)를 최대화할 수 있는 low-dimensional(저차원) 피쳐 공간을 학습시켰다. 실제로 기존의 존재하는 데이터들을 대상으로 수행을 해봤는데 괜찮은 결과가 나왔다.
- 뭐, 실제로 해봤는데 잘 된다니까 됐죠. 뭐. 저는 바로 한번 사용해보려고 합니다.
- 다만 표현 중에 “contiuous representation”이라는 것이 무엇인지는 좀 애매하네요. 실제 네트워크는 discrete한 representation인데(끊어져있거나, 이어져있거나 하니까), 여기서는 그것을 불분명하게 학습하므로 그렇게 되는 것인가? 싶기도 하구요.
recap: word2vec
- 우선 그나마 익숙한 representational learning인 word2vec부터 다시 복습을 해봅시다. word2vec은 단어를 벡터로서 표현하는 학습방법입니다. 앞서 나온 말처럼 어떠 차원속에 워드의 위치를 조정해 나가는 학습방법이죠.
- skip-gram과 CBOW(continuous bag of word)라는 방법이 있는데 근처의 워드들로 중심의 워드를 예측하거나, 중심의 워드로 근처의 워드를 예측하는 방법으로 마치 듀얼리틱한 방법입니다. 간단하게 말하면 실제 문장들에서 비슷한 위치에 있는 워드들은 n차원의 벡터 공간에 전사하더라도 비슷한 위치를 가지게 될 것이다, 라는 것이 이 방법론이 가지고 있는 가정이죠.
- input layer는 앞뒤 윈도우를 고려해서 sparse vector로 들어오고 우리가 원하는 크기인 n차원으로 projection layer로 옮겨지고(아마도 fully connected layer) 이렇게 저렇게 히든 레이어를 쌓은 다음 다시 inverse projection layer, 그 다음 중심어가 output layer로 설계되죠. 문장 속에 있는 데이터를 마구마구 학습시킨 다음에 학습이 충분히 된 다음에는 projection layer의 값만 가져옵니다 그게 각 word들이 n 차원에서 가지는 벡터의 값이니까요.
similarity between word2vec and node2vec
- 그런데 뭔가 word2vec이 node2vec과 유사하다는 생각이 들지 않나요? 예를 들어 “I am a boy. “라는 데이터가 있다고 하면, 여기서 window size를 1로 잡았을 때, 중심어 ‘a’에 해당하는 input 값들은 ‘am’과 ‘boy’가 있죠. 즉 이건 마치 네트워크에서도 동일하게 서로 연결되어 있는 놈과 아닌 놈을 구별하는 것처럼 여겨지게 됩니다.
- 즉 비슷하게, node2vec도 같은 방식으로 처리할 수 있지 않을까요? 네트워크 상에서 중심 노드를 output layer로 두고, 이 아이와 연결된 모든 노드를 input layer로 두고, projection layer를 두고 진행하면 비슷하게 만들 수 있지 않을까 싶습니다. 각각 벡터의 크기는 adjacency matrix를 그대로 사용해도 되지 않을까 라는 생각도 해봅니다만, 흠, 이렇게 하면 좀 문제가 있을까 싶기도 하네요. 뭐 상관없을 것 같기도 하고.
- 아무튼 중요한 개념은 word2vec이나 node2vec이나 생각보다 큰 차이가 있다고 보기는 어렵다는 말입니다. 비슷하게 학습될 수 있는 것 같아요.
- word2vec의 경우 corpus를 사용해서 학습합니다. 간단히 생각하면 ‘문장’이라고 생각해도 상관없구요.
- 그렇다면 node2vec에서는 corpus 대신에 무엇을 넣어야 할까요? 이 부분이 word2vec과 node2vec을 가르는 차이점입니다.
- 이렇게 graph에서 적합한 corpus를 뽑아내는 것이 일종의 sampling strategy로서 작동하고,
- 뽑아낸 corpus를 skip-gram에 돌려서 학습시키면 우리가 하려는 node2vec이 완성되게 됩니다.
- 이렇게 쓰고 나면 매우 쉬워지죠.
back: node2vec
- word2vec에서 학습하는 corpuse들은 directed network죠. 예를 들어 “I am a boy”라는 문장이 있다면 이는 “(I) -> (am) -> (a) -> (boy)”라고 해석될 수 있습니다. 즉 한 방향으로 연결된 네트워크죠.
- 그러나, node2vec에서 사용해야 하는 network의 경우는 이와 다릅니다. 보통 Graph는 (Vertex, Edges, Weight)로 구성되어 있습니다. word2vec의 좀 더 generlized form이 node2vec이 되는 것이죠. 자, 그럼 여기서 어떻게 sampling해서 뽑아내는 걸까요?
sampling strategy: BFS and DFS
- 우리가 대상으로 하는 데이터인 네트워크의 경우 선형적으로 존재하지 않으므로 여기서 선형적인 무엇을 뽑아내주는 것이 필요합니다. 이것이 여기서 말하는 sampling 전략이죠.
- 그런데 우리는 이미 이러한 종류의 전략을 알고 있습니다. Breadth First Search, Depth First Search가 그 예죠. Tree를 탐색할 때 넓게 탐색하느냐, 깊게 탐색하느냐 에 따라서 결과는 달라집니다. 즉 sampling할 때도 넓게 탐색해서 넣느냐, 깊게 탐색하느냐에 따라서 node의 벡터표현이 달라질 것 같습니다. 난 듈-다 를 생각하는 경우 적합한 하이퍼 파라미터를 잘 조절하면서 진행해야겠죠.
- 이를 좀 더 설명하자면, BFS로 샘플링할 경우 네트워크의 미시적인 특성이 강조되고, DFS로 샘플링할 경우 네트워크의 거시적인 특성이 강조됩니다.
- 다시, BFS로 샘플링할 경우 Network Homophily, “비슷한 노드는 서로 공통적으로 연결되어 있는 노드가 많다”는 개념을 기반으로 하고,
- DFS로 샘플링할 경우 Structural Equivalence, “비슷한 노드는 네트우크에서 서로 비슷한 구조적인 위치에 존재한다”는 개념을 지지합니다.
- 둘다 잘 뽑아낼 수 있으면 좋겠지만, 이 둘의 개념은 어느 정도 서로 배반적인 부분이 있기 때문에, 목적에 따라서 다르게 embedding하는 것이 필요하다고 생각됩니다.
hyper parameter p and q
- 즉, 이렇게 BFS를 할 것인지, DFS를 할 것인지를 조절하기 위해서 여기서는 두 hyper-parameter를 사용합니다.
- 아래 그림으로 보시는 것이 더 좋을 수 있습니다(normalized 되어 있지 않습니다)
- p가 높아지면, 이전에 방문했던 노드로는 잘 가지 않고, 새로운 노드로 가는 경향성이 높아지며,
- q가 낮아지면, 새로운 노드로 가는 경향성이 높아지죠
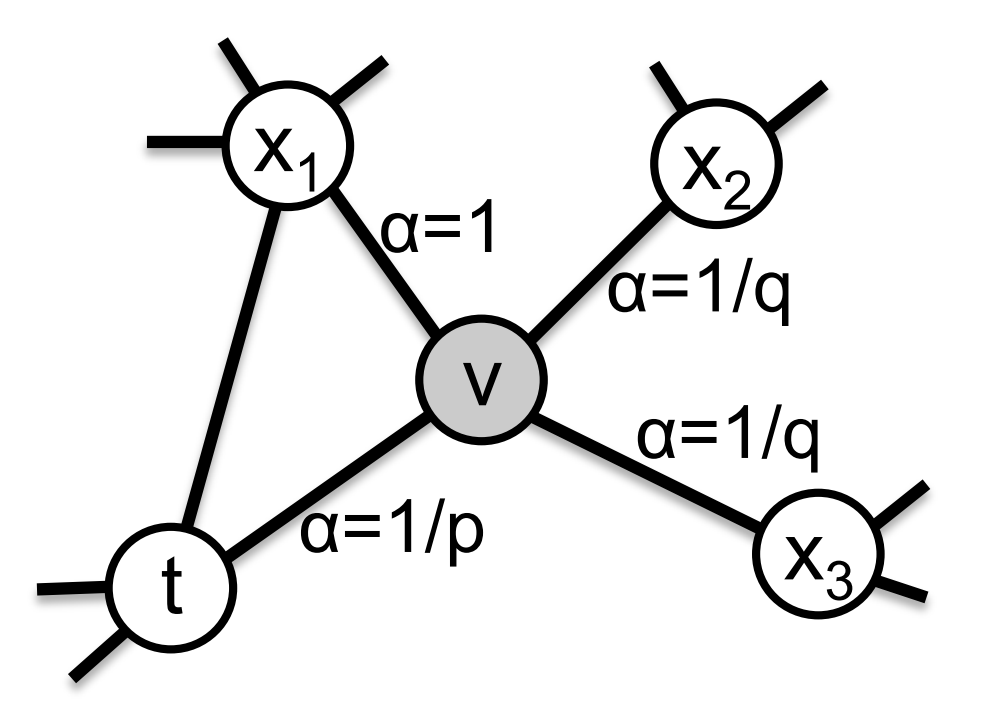
- 즉, Return parameter p, In-out parameter q를 각각 조절하여 관찰하려고 하는 네트워크의 특성을 조절할 수 있겠죠.
- 논문에서는 계산상의 이점에 대해서도 말하고 있는데, 저는 그 부분은 제외하게습니다 하하하하.
case study
- 논문에서는 소설 레미제라블에서 동시에 등장하는 인물들에 대해서 네트워크를 모델링하고 node2vec을 사용해봅니다.
- 77개의 노드, 254개의 엣지가 있고 16 차원으로 전사하고, 16차원으로 나온 feature들에 대해서 K-means clustering을 수행하였습니다.
- 첫번째 실험에서는 homophily를 강조하기 위해서 p는 1, q는 0.5로 수행하고, 두번째 실험에서는 structural equivalence 특성을 강조하기 위해서 p=1, q=2로 세팅하고 수행하였습니다.
- 그 결과로 아래 그림처럼 hyper parameter에 따라서 서로 다른 결과가 나오는 것을 알 수 있죠.

나머지 이야기.
- spectral clustering, DeepWalk, LINE 등의 기법으로 feature extraction한 것과 Node2vec을 비교해서 multi-label classification에 사용해보니까 node2vec이 더 좋았다는 이야기.
- parameter들에 따라서 해당 방법론의 성능이 얼마나 민감하게 작동하는지를 정리함.
- 네트워크의 connectivity를 유지한 상태로 50%의 edge를 자르고, link prediction을 예측해봄.
- 기존의 방법들인 common neighbor 등으로 예측했을 때를 base line으로 두고 link prediction을 에측해봤다는데 여기서 Node2vec으로 표현된 두 Node에 대해서 어떻게 link prediction을 예측했는지에 대해서 안 나옴. binary operator를 사용했다는게 대략 vector distance등처럼 벡터간의 연산을 통해서 에측한 것으로 보임. 어쨌거나, 이렇게 해보니까. 괜찮더라는 이야기고, node뿐만 아니라 edge에 대해서도 충분히 유효하게 진행할 수 있다는 것 이야기임.
- linke prediction도 일종의 binary classification 문제인데 두 노드의 값을 가져와서 실제로 Link 가 발생하는지를 간단한 neural network를 통해 만들어볼 수도 있었을텐데 이렇게는 왜 안했을까, 해볼 필요가 없다고 느꼈던걸까 하핫
- 기존의 방법들인 common neighbor 등으로 예측했을 때를 base line으로 두고 link prediction을 에측해봤다는데 여기서 Node2vec으로 표현된 두 Node에 대해서 어떻게 link prediction을 예측했는지에 대해서 안 나옴. binary operator를 사용했다는게 대략 vector distance등처럼 벡터간의 연산을 통해서 에측한 것으로 보임. 어쨌거나, 이렇게 해보니까. 괜찮더라는 이야기고, node뿐만 아니라 edge에 대해서도 충분히 유효하게 진행할 수 있다는 것 이야기임.
- 아무튼 discussion and conclusion에서는
- 전통적인 exploration-explotation tradeoff를 활용해서 네트워크를 통해 보려는 부분을 정확하게(local or global) 표현할 수 있다는 것
- link prediction에 대해서도 잘 작동하는 것 같은데 특히 harmard binary operator에 대해서만 잘 작동하는 것은 이유를 좀 찾아봐야 할 것 같음
- 기타의 다른 graph 관련 학습에 대해서도 잘 쓸 수 있지 않을까? 하는 것들
wrap-up
- 처음에는 그냥 블로그에 있는 내용들이나 보고 정리하려고 했는데 어쩌다보니 논문을 읽게 되었습니다. 음 조금 신기했던 것은 생각보다 논문이 존나 쉽게 읽혔다는 것이죠. 하하핫
- 아무튼 정리를 다시 하자면 다음과 같습니다.
- node2vec은 word2vec과 유사한 학습 방법론임, skip-gram을 사용함
- 그런데 여기서 word2vec은 이미 corpus 혹은 sequence가 있는 반면 node2vec은 없음. 그래서 node2vec은 이 sequence를 뽑아내야 함
- 이 sequence를 뽑아내는 것이 node2vec에서 개발한 sampling strategy이고 p, q 의 hyper parameter를 조절해서 local structure, global structure 중에서 무엇을 더 중요하게 인식하게 할지를 정해야함
- 실제로 다른 feature engineering 방법론들을 벤치마크로 multi classification을 해보니까 node2vec이 더 잘 작동함
- 그리고 단지 node뿐만 아니라 binary operator를 사용해서 link prediction에 대해서도 잘 작동하는 것을 알 수 있었음.
- 개념적으로는 대략 알겠고요. 그렇다면 이제 이걸 직접 코딩을 해보면 좋겠는데 이미 이 분께서 만들어두셨습니다. pip로 다운받을 수도 있어요.
- 아무튼 그러핟면 다음에는 node2vec의 파이썬 라이브러리를 정리해서 써보도록 하겠습니다 하하핫
댓글남기기